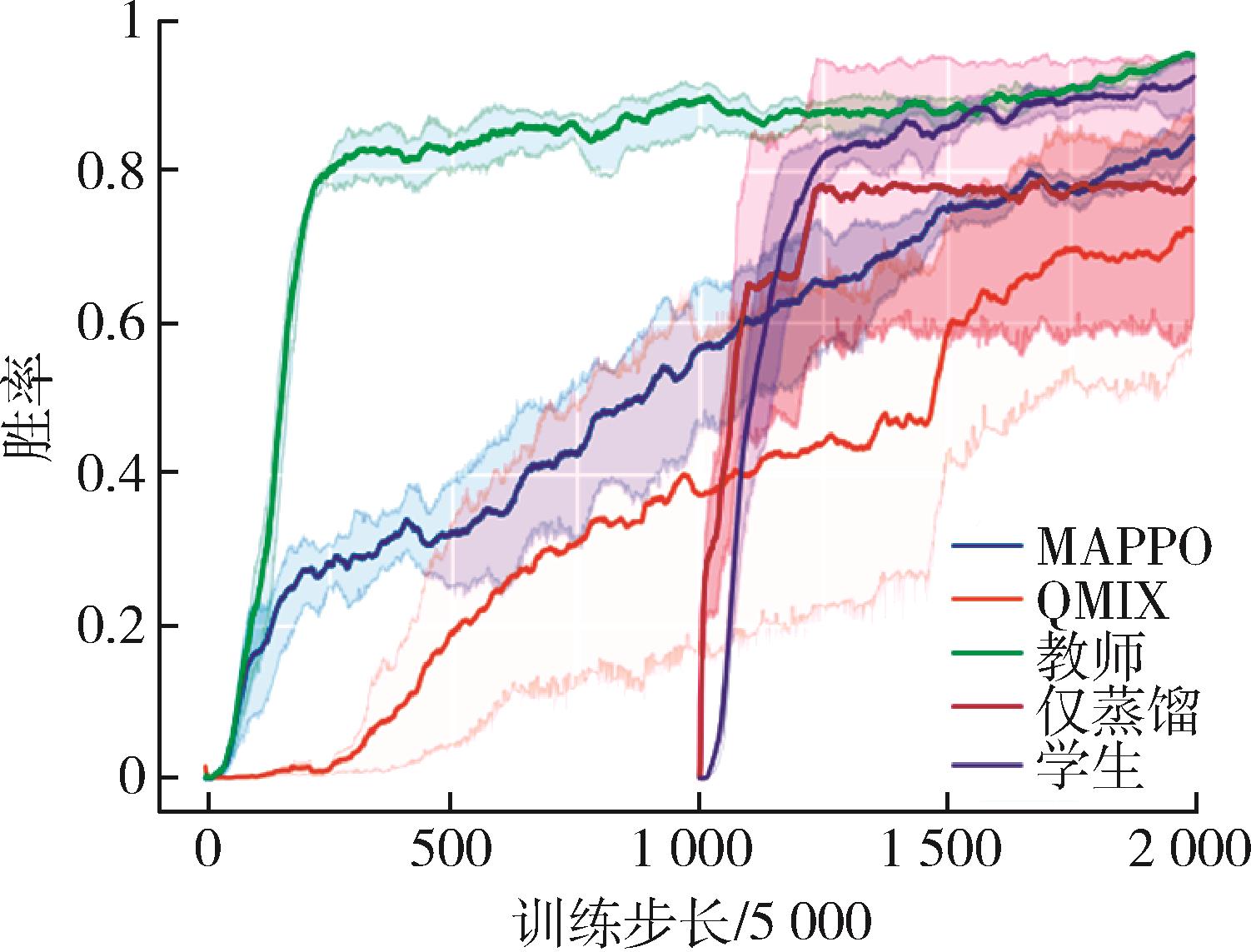
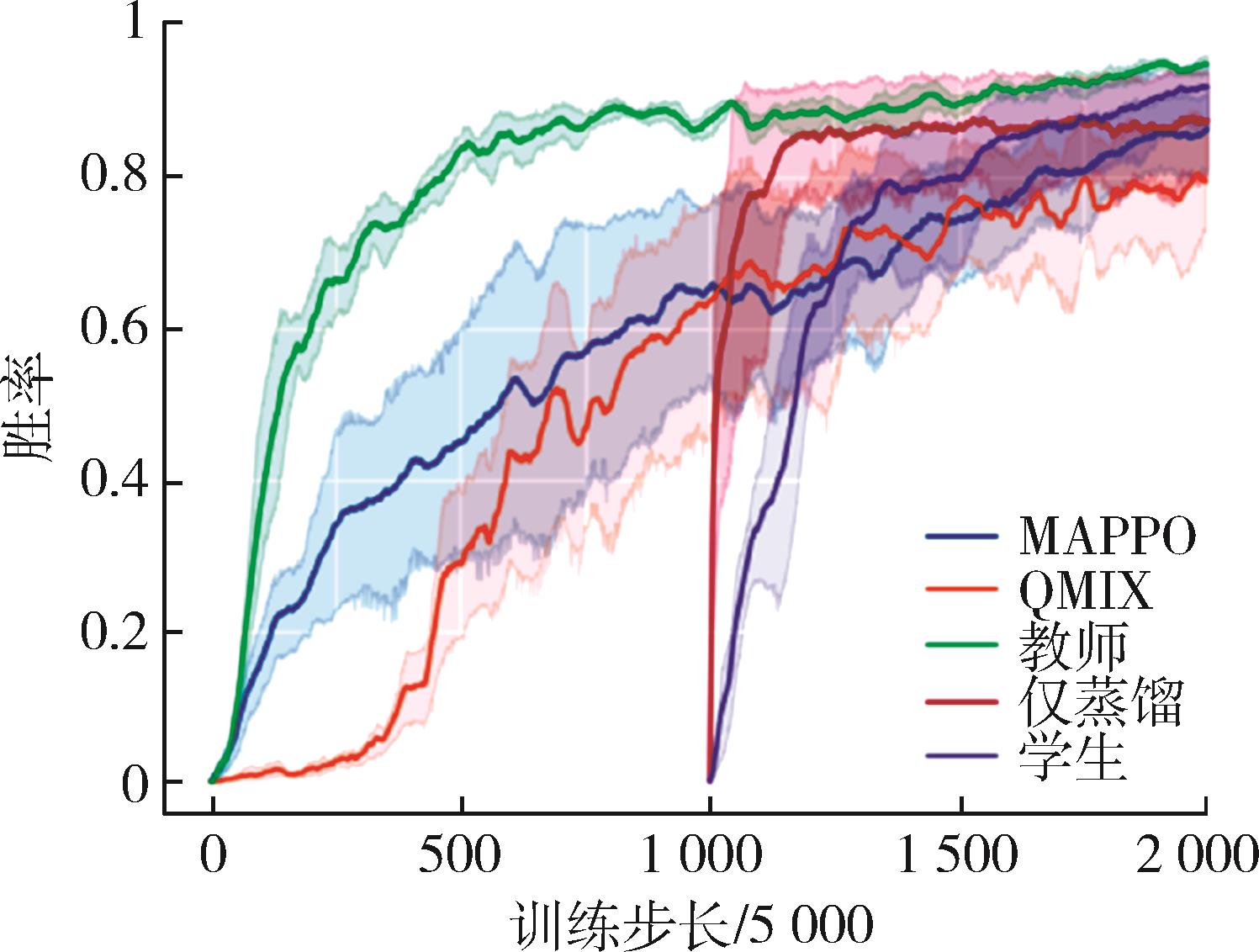
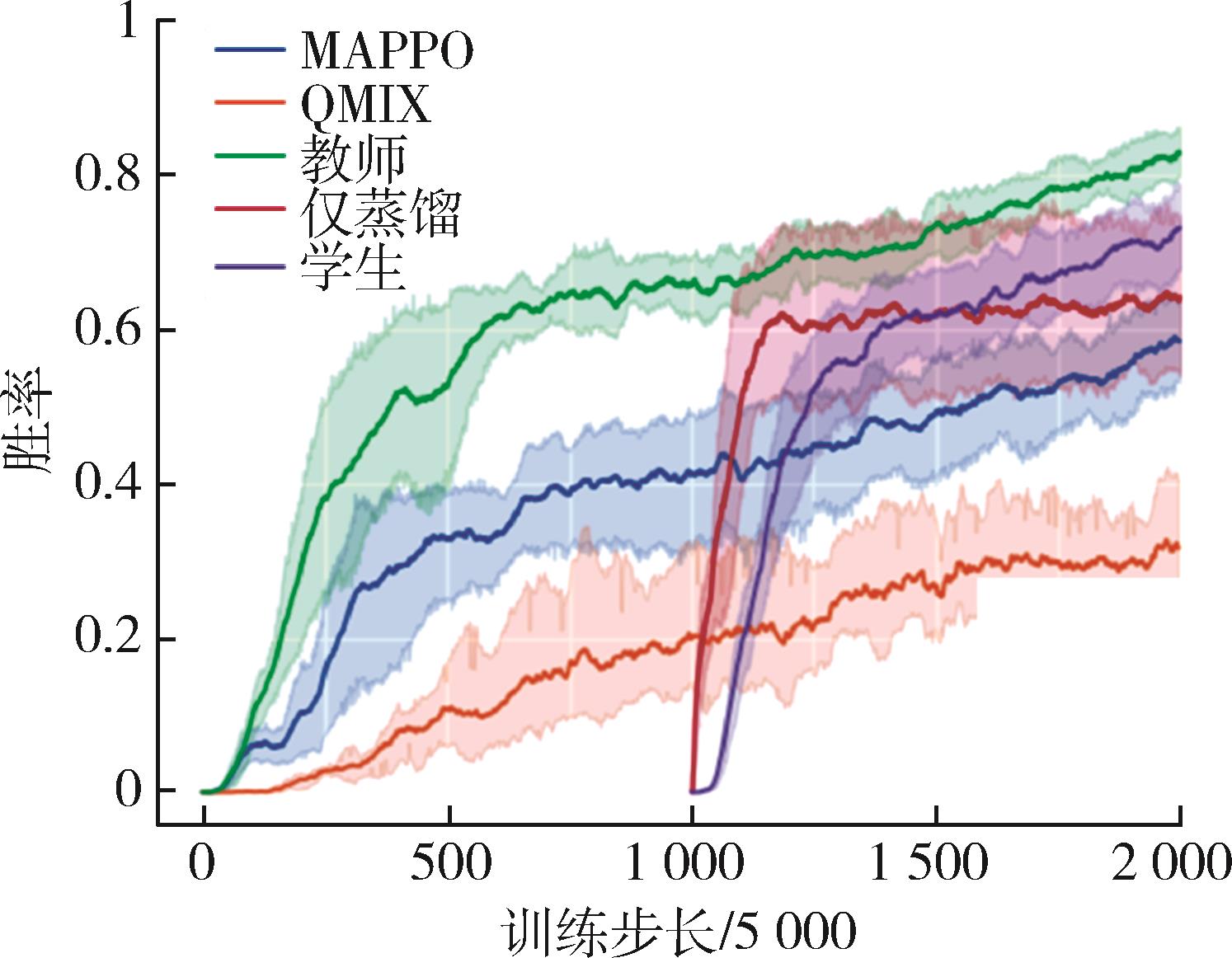
| 1 |
梁星星, 冯旸赫, 马扬, 等. 多Agent深度强化学习综述[J]. 自动化学报, 2020, 46(12): 2537-2557.
|
|
LIANG Xingxing, FENG Yanghe, MA Yang, et al. Deep Multi-agent Reinforcement Learning: A Survey[J]. Acta Automatica Sinica, 2020, 46(12): 2537-2557.
|
| 2 |
DU Wei, DING Shifei. A Survey on Multi-agent Deep Reinforcement Learning: From the Perspective of Challenges and Applications[J]. Artificial Intelligence Review, 2021, 54(5): 3215-3238.
|
| 3 |
MATIGNON L, JEANPIERRE L, MOUADDIB A I. Coordinated Multi-Robot Exploration Under Communication Constraints Using Decentralized Markov Decision Processes[C]∥Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence. Palo Alto, CA, USA: AAAI Press, 2012: 2017-2023.
|
| 4 |
向锦武, 董希旺, 丁文锐, 等. 复杂环境下无人集群系统自主协同关键技术[J]. 航空学报, 2022, 43(10): 325-357.
|
|
XIANG Jinwu, DONG Xiwang, DING Wenrui, et al. Key Technologies for Autonomous Cooperation of Unmanned Swarm Systems in Complex Environments[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(10): 325-357.
|
| 5 |
SILVER D, HUANG A, MADDISON C J, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search[J]. Nature, 2016, 529: 484-489.
|
| 6 |
LI Bin. Hierarchical Architecture for Multi-Agent Reinforcement Learning in Intelligent Game[C]∥2022 International Joint Conference on Neural Networks (IJCNN). Piscataway, NJ, USA: IEEE, 2022: 1-8.
|
| 7 |
丁季时雨, 孙科武, 董博, 等. 基于元课程强化学习的多智能体协同博弈技术[J]. 现代防御技术, 2022, 50(5): 36-42.
|
|
DING Jishiyu, SUN Kewu, DONG Bo, et al. Multi-agent Autonomous Cooperative Confrontation Based on Meta Curriculum Reinforcement Learning[J]. Modern Defence Technology, 2022, 50(5): 36-42.
|
| 8 |
李盛祥. 基于强化学习的多智能体协同关键技术及应用研究[D]. 郑州: 战略支援部队信息工程大学, 2021.
|
|
LI Shengxiang. Research on Multiagent Cooperation and Applications Based on Reinforcement Learning[D]. Zhengzhou: PLA Strategic Support Force Information Engineering University, 2021.
|
| 9 |
RASHID T, SAMVELYAN M, DE WITT C S, et al. Monotonic Value Function Factorisation for Deep Multi-agent Reinforcement Learning[J]. The Journal of Machine Learning Research, 2020, 21(1): 7234-7284.
|
| 10 |
SON K, KIM D, KANG W J, et al. QTRAN: Learning to Factorize with Transformation for Cooperative Multi-agent Reinforcement Learning[C]∥Proceedings of the 36th International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2019: 5887-5896.
|
| 11 |
熊丽琴, 曹雷, 赖俊, 等. 基于值分解的多智能体深度强化学习综述[J]. 计算机科学, 2022, 49(9): 172-182.
|
|
XIONG Liqin, CAO Lei, LAI Jun, et al. Overview of Multi-agent Deep Reinforcement Learning Based on Value Factorization[J]. Computer Science, 2022, 49(9): 172-182.
|
| 12 |
YU Chao, VELU A, VINITSKY E, et al. The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games[C]∥Advances in Neural Information Processing Systems. San Francisco, CA, USA: Curran Associates Inc., 2022: 24611-24624.
|
| 13 |
LOWE R, WU Yi, TAMAR A, et al. Multi-agent Actor-Critic for Mixed Cooperative-Competitive Environments[C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2017: 6382-6393.
|
| 14 |
FOERSTER J N, FARQUHAR G, AFOURAS T, et al. Counterfactual Multi-agent Policy Gradients[C]∥Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto, CA, USA: AAAI Press, 2018: 2974-2982.
|
| 15 |
JIANG Jiechuan, LU Zongqing. Learning Attentional Communication for Multi-agent Cooperation[C]∥Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2018: 7265-7275.
|
| 16 |
DAS A, GERVET T, ROMOFF J, et al. TarMAC: Targeted Multi-agent Communication[C]∥Proceedings of the 36th International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2019: 1538-1546.
|
| 17 |
TSENG W C, WANG T H J, LIN Y C, et al. Offline Multi-agent Reinforcement Learning with Knowledge Distillation[C]∥Advances in Neural Information Processing Systems. San Francisco, CA, USA: Curran Associates Inc., 2022: 226-237.
|
| 18 |
ZHAO Jian, HU Xunhan, YANG Mingyu, et al. CTDS: Centralized Teacher with Decentralized Student for Multi-agent Reinforcement Learning[J/OL]. IEEE Transactions on Games. (2022-12-27) [2023-12-16]. .
|
| 19 |
闫超, 相晓嘉, 徐昕, 等. 多智能体深度强化学习及其可扩展性与可迁移性研究综述[J]. 控制与决策, 2022, 37(12): 3083-3102.
|
|
YAN Chao, XIANG Xiaojia, XU Xin, et al. A Survey on Scalability and Transferability of Multi-agent Deep Reinforcement Learning[J]. Control and Decision, 2022, 37(12): 3083-3102.
|
| 20 |
CZARNECKI W M, PASCANU R, OSINDERO S, et al. Distilling Policy Distillation[C]∥Proceedings of the Twenty-second International Conference on Artificial Intelligence and Statistics. Chia Laguna Resort, Sardinia, Italy: PMLR, 2019: 1331-1340.
|
| 21 |
VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al. Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning[J]. Nature, 2019, 575: 350-354.
|


 ), Xiaopeng XU, Dong WANG
), Xiaopeng XU, Dong WANG