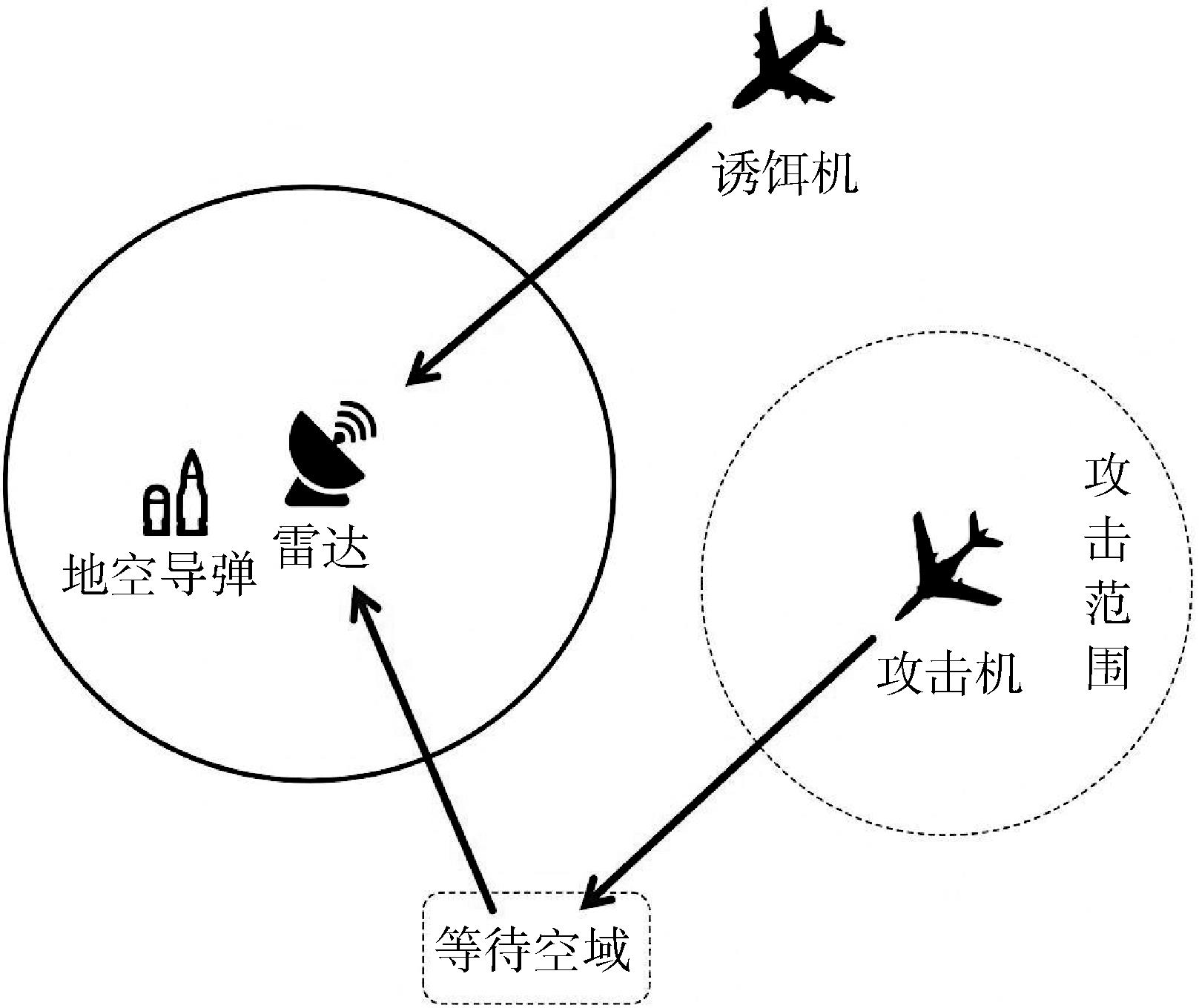
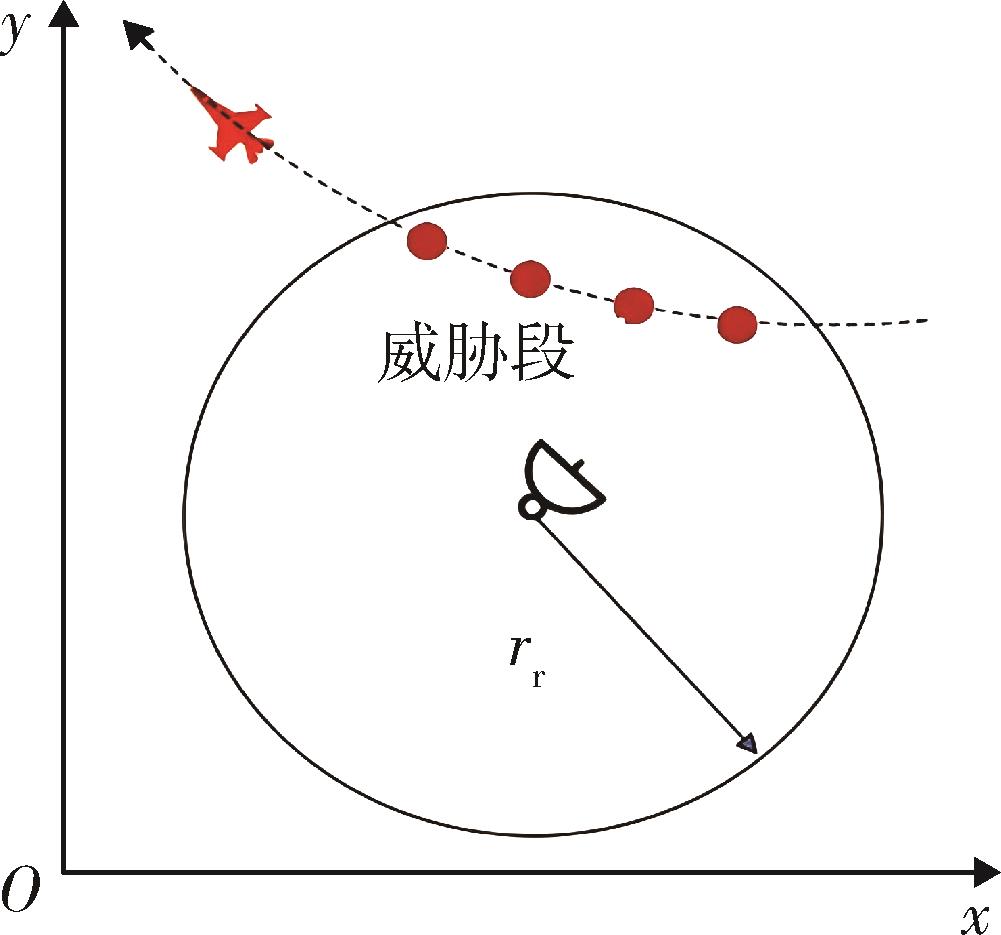
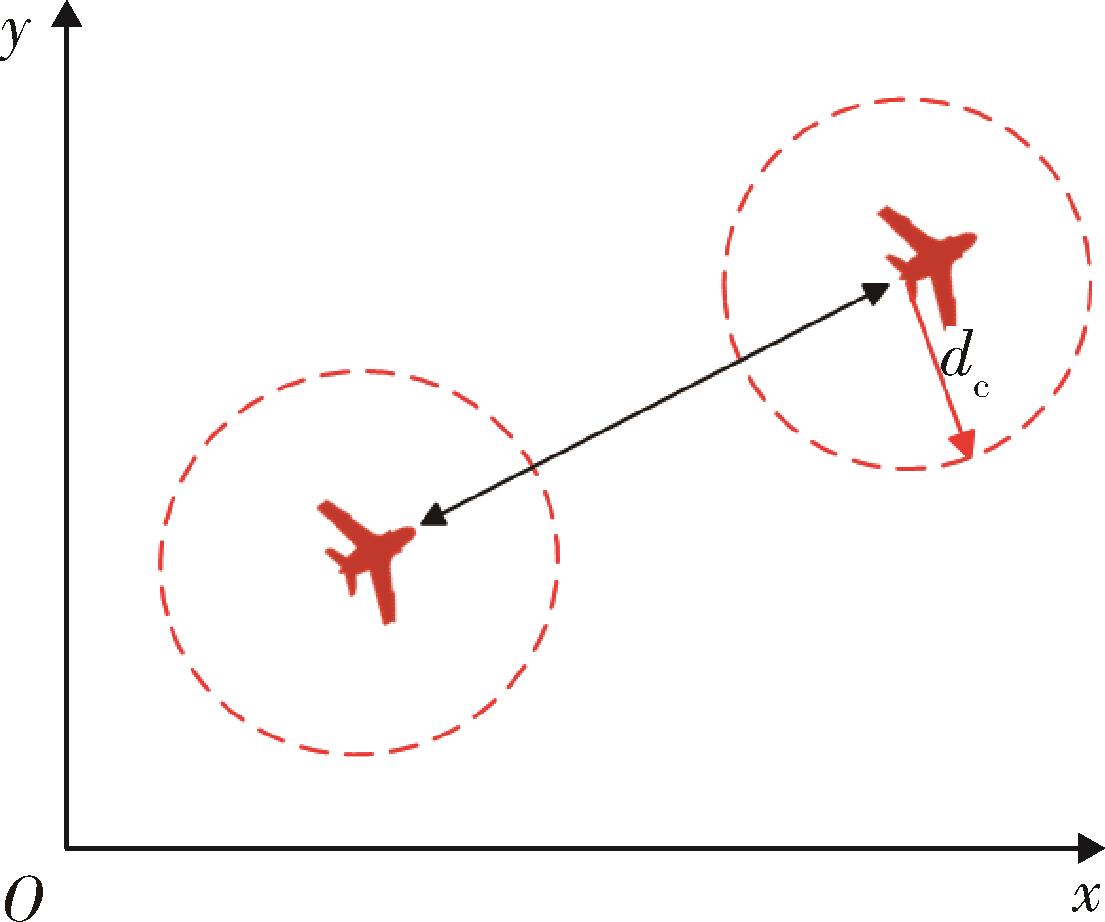
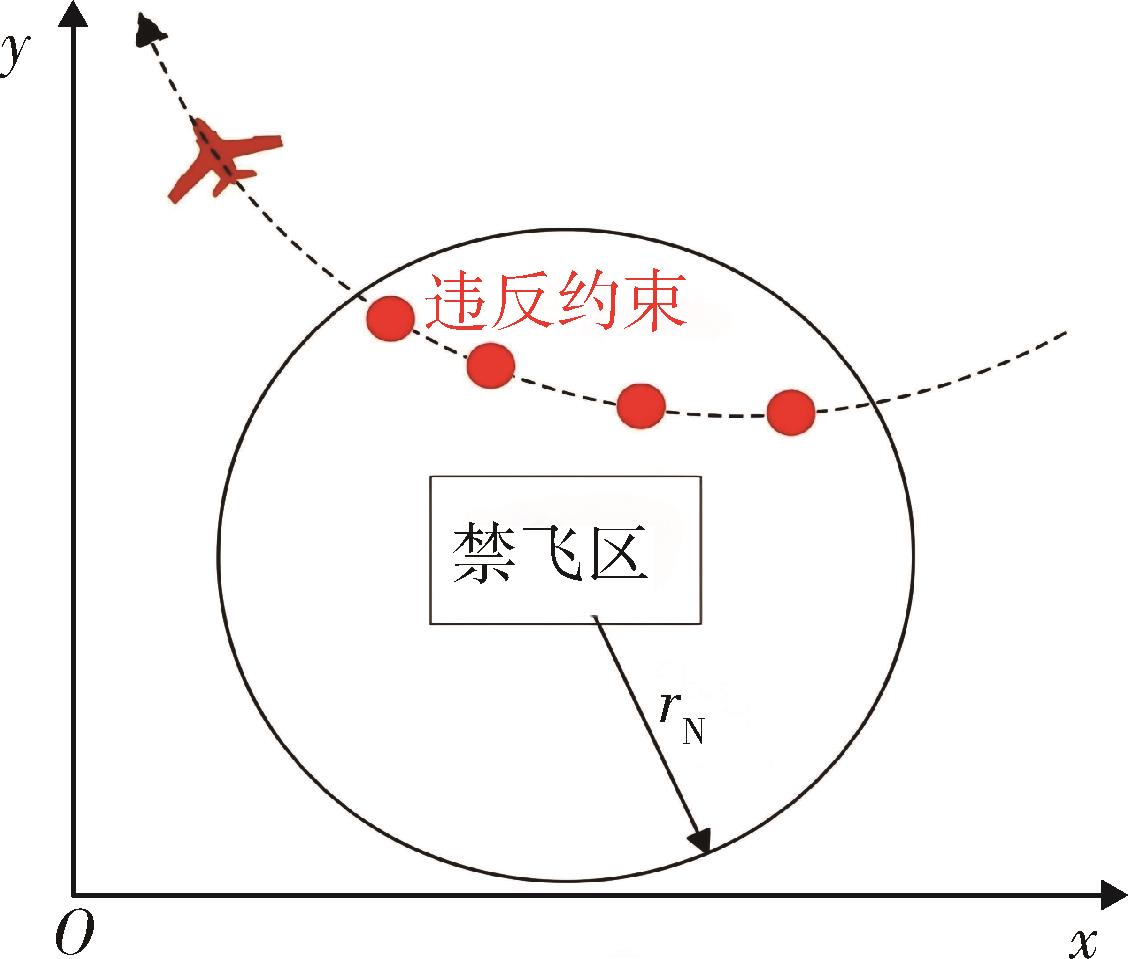
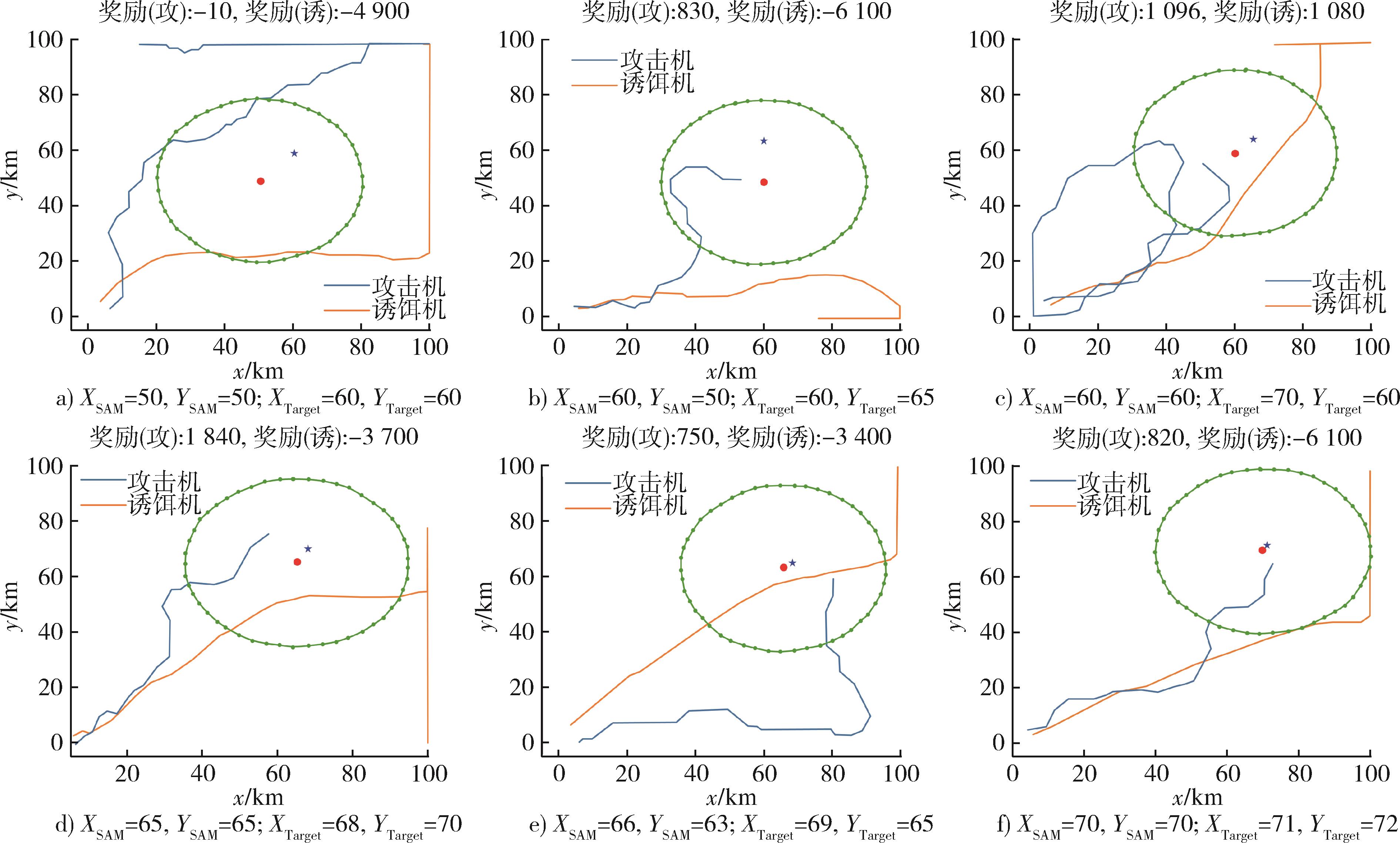
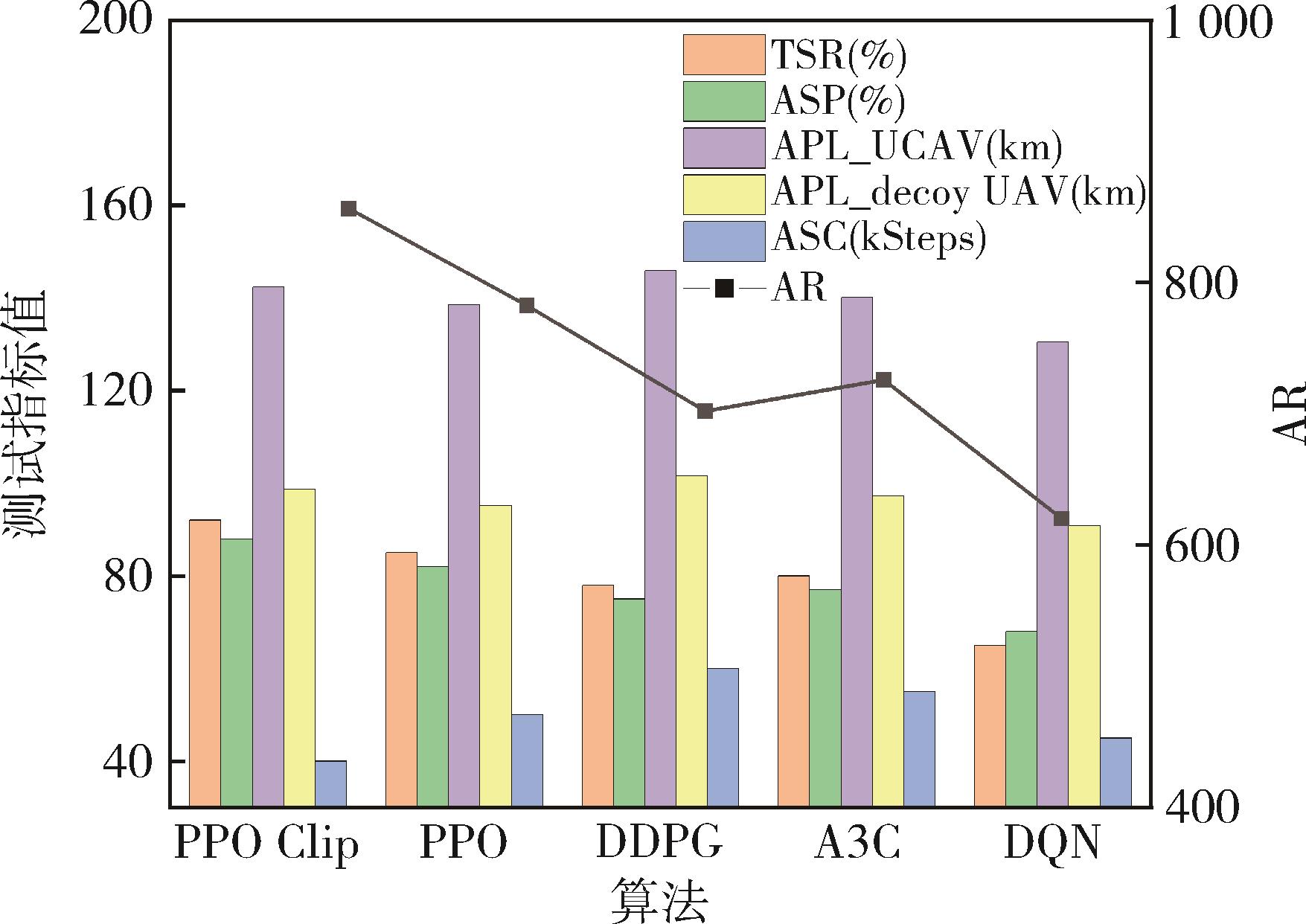
| [1] |
韦振汉, 唐辉, 杨煜, 等. 基于强化学习的多无人机航迹规划[J]. 现代防御技术, 2025, 53(5): 136-144.
|
|
WEI Zhenhan, TANG Hui, YANG Yu, et al. Multi-UAV Path Planning Based on Reinforcement Learning[J]. Modern Defence Technology, 2025, 53(5): 136-144.
|
| [2] |
费陈, 赵亮, 贺拥亮, 等. 城市环境下无人机群目标打击航迹规划[J]. 现代防御技术, 2025, 53(1): 1-10.
|
|
FEI Chen, ZHAO Liang, HE Yongliang, et al. Trajectory Planning for UAV Swarm Target Strikes in Urban Environments[J]. Modern Defence Technology, 2025, 53(1): 1-10.
|
| [3] |
潘楠, 刘海石, 陈启用, 等. 多基地多目标无人机协同任务规划算法研究[J]. 现代防御技术, 2021, 49(2): 49-56.
|
|
PAN Nan, LIU Haishi, CHEN Qiyong, et al. Study on Cooperative Mission Planning Algorithm for Multi-base and Multi-target UAV[J]. Modern Defence Technology, 2021, 49(2): 49-56.
|
| [4] |
房霄, 曾贲, 宋祥祥, 等. 基于深度强化学习的舰艇空中威胁行为建模[J]. 现代防御技术, 2020, 48(5): 59-66.
|
|
FANG Xiao, ZENG Ben, SONG Xiangxiang, et al. Modeling of Air Target Threat to Warship Based on Deep Reinforcement Learning[J]. Modern Defence Technology, 2020, 48(5): 59-66.
|
| [5] |
LI Qiuxiang, WU Jianping. Efficient Network Attack Path Optimization Method Based on Prior Knowledge-Based PPO Algorithm[J]. Cybersecurity, 2025, 8(1): 15.
|
| [6] |
屈文涛, 谢韩彧, 刘鑫, 等. 基于改进遗传算法的油气管道无人机航迹规划[J]. 科学技术与工程, 2024, 24(27): 11901-11908.
|
|
QU Wentao, XIE Hanyu, LIU Xin, et al. Path Planning of UAV in Oil and Gas Pipeline Based on Improved Genetic Algorithm[J]. Science Technology and Engineering, 2024, 24(27): 11901-11908.
|
| [7] |
唐颂, 吴建源. 基于改进遗传算法的协同航迹规划方法[J]. 电光与控制, 2024, 31(7): 8-12, 26.
|
|
TANG Song, WU Jianyuan. A Cooperative Trajectory Planning Method Based on Improved Genetic Algorithm[J]. Electronics Optics & Control, 2024, 31(7): 8-12, 26.
|
| [8] |
王瑶, 任安虎, 任洋洋. 改进蚁群算法的无人机航迹规划[J]. 电光与控制, 2024, 31(4): 43-48.
|
|
WANG Yao, REN Anhu, REN Yangyang. An Improved Ant Colony Algorithm for UAV Trajectory Planning[J]. Electronics Optics & Control, 2024, 31(4): 43-48.
|
| [9] |
XU Chentao, ZHOU Shiqi, LIANG Maohan, et al. Reliable Vessel Trajectory Clustering: A Maritime Shipping Network-Driven Computational Method[J]. Ocean Engineering, 2025, 336: 121691.
|
| [10] |
郝昱. 基于强化学习的无人机火灾救援航迹规划[D]. 赣州: 江西理工大学, 2023.
|
|
HAO Yu. Route Planning for Fire Rescue of Unmanned Aerial Vehicles Based on Reinforcement Learning[D]. Ganzhou: Jiangxi University of Science and Technology, 2023.
|
| [11] |
周枫. 基于智能算法的无人机航迹规划研究[D]. 镇江: 江苏科技大学, 2023.
|
|
ZHOU Feng. Research on Unmanned Aerial Vehicle Path Planning Based on Intelligent Algorithms[D]. Zhenjiang: Jiangsu University of Science and Technology, 2023.
|
| [12] |
王力, 赵全海, 黄石磊. 面向物流机器人的改进Q-Learning动态避障算法研究[J]. 计算机测量与控制, 2025, 33(3): 267-274.
|
|
WANG Li, ZHAO Quanhai, HUANG Shilei. Improved Q-Learning Dynamic Obstacle Avoidance Algorithm for Logistics Robots[J]. Computer Measurement & Control, 2025, 33(3): 267-274.
|
| [13] |
WANG Meng, GUI Xueqian, YAN Huaicheng, et al. Event-Triggered Optimal Bipartite Consensus Control for Constrained Multiagent Systems via Internal Reinforce Q-Learning[J]. IEEE Transactions on Cybernetics, 2025, 55(8): 3852-3865.
|
| [14] |
杨淞匀, 王杭先, 林鹏. 基于DDPG算法的无人船避障路径规划[J]. 信息技术, 2025, 49(3): 1-7, 15.
|
|
YANG Songyun, WANG Hangxian, LIN Peng. Obstacle Avoidance Path Planning of Unmanned Surface Vessels Based on DDPG Algorithm[J]. Information Technology, 2025, 49(3): 1-7, 15.
|
| [15] |
桑垚, 马晓宁. 改进奖励函数的深度强化学习路径规划方法[J]. 计算机应用与软件, 2025, 42(1): 271-276.
|
|
SANG Yao, MA Xiaoning. Path Planning Method of Deep Reinforcement Learning with Improved Reward Function[J]. Computer Applications and Software, 2025, 42(1): 271-276.
|
| [16] |
周从航, 李建兴, 石宇静, 等. 深度强化学习在无人机编队路径规划中的应用[J]. 电光与控制, 2024, 31(10): 27-33.
|
|
ZHOU Conghang, LI Jianxing, SHI Yujing, et al. Application of Deep Reinforcement Learning in Path Planning of UAV Formation[J]. Electronics Optics & Control, 2024, 31(10): 27-33.
|
| [17] |
李京涛. 基于强化学习的多智能体救援策略研究[D]. 杭州: 浙江科技大学, 2024.
|
|
LI Jingtao. Research on Multi-agent Rescue Strategy Based on Reinforcement Learning[D]. Hangzhou: Zhejiang University of Science and Technology, 2024.
|
| [18] |
LUO Wangbin, WANG Xiang, HAN Fang, et al. Research on LSTM-PPO Obstacle Avoidance Algorithm and Training Environment for Unmanned Surface Vehicles[J]. Journal of Marine Science and Engineering, 2025, 13(3): 479.
|
| [19] |
WU Yaohuan, XIE Nan. Design of Digital Low-Carbon System for Smart Buildings Based on PPO Algorithm[J]. Sustainable Energy Research, 2025, 12(1): 9.
|
| [20] |
ZHANG Xiaoya, ZHANG Yuyang, DONG Ping, et al. PPORM: A PPO-Assisted Packet Reordering Mechanism of Heterogeneous VANETs for Enhancing Goodput and Stability in Fog Computing[J]. Vehicular Communications, 2025, 53: 100894.
|
| [21] |
WANG Junwei, ZENG Zilin, SHANG Peng. Smooth Clip Advantage PPO in Reinforcement Learning[J]. Journal of Physics: Conference Series, 2023, 2513(1): 012005.
|