现代防御技术 ›› 2022, Vol. 50 ›› Issue (5): 36-42.DOI: 10.3969/j.issn.1009-086x.2022.05.006
Ji-shi-yu DING, Ke-wu SUN, Bo DONG, Xi-rui YANG, Chang-chao FAN, Zhe MA
摘要:
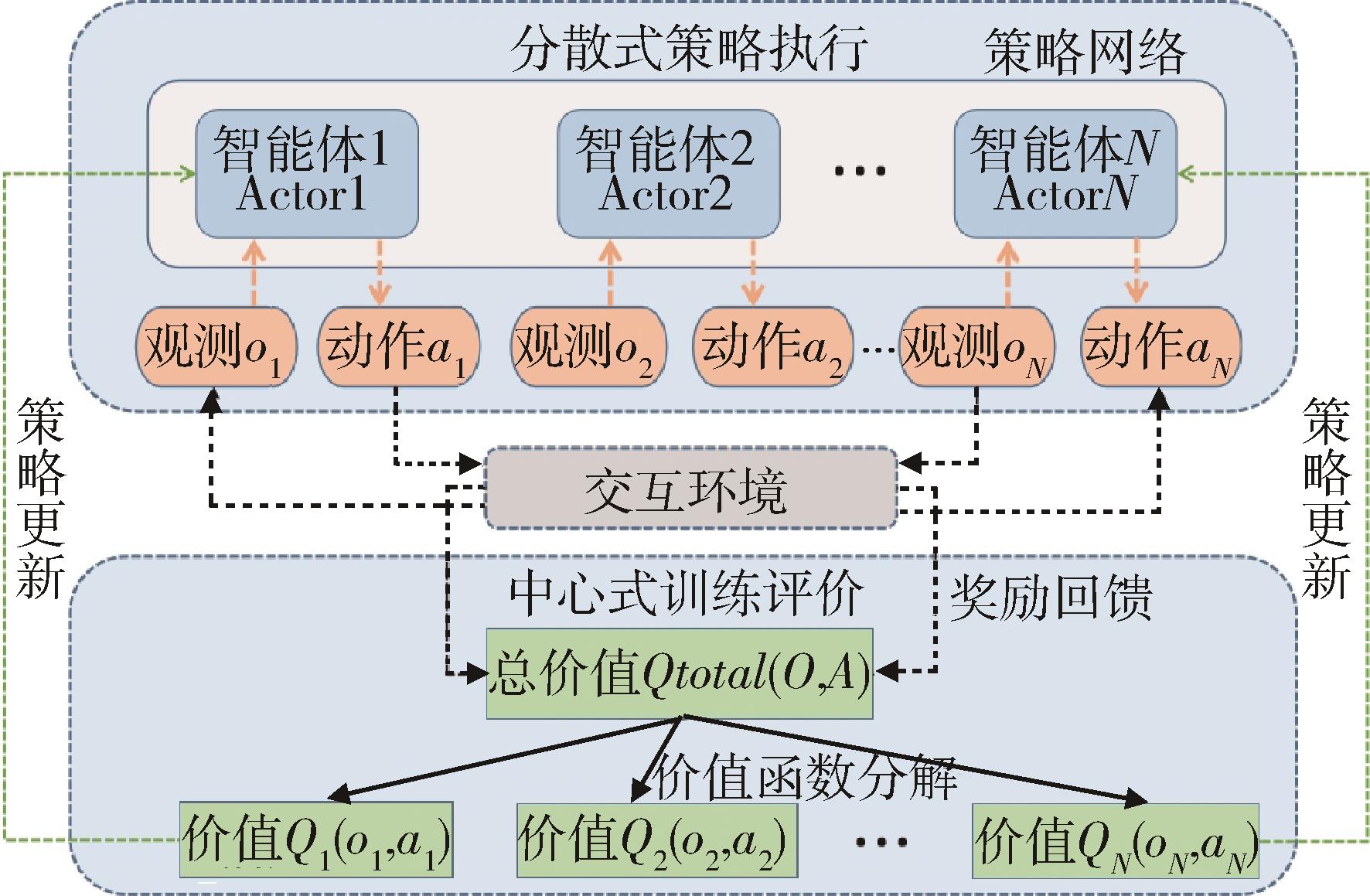
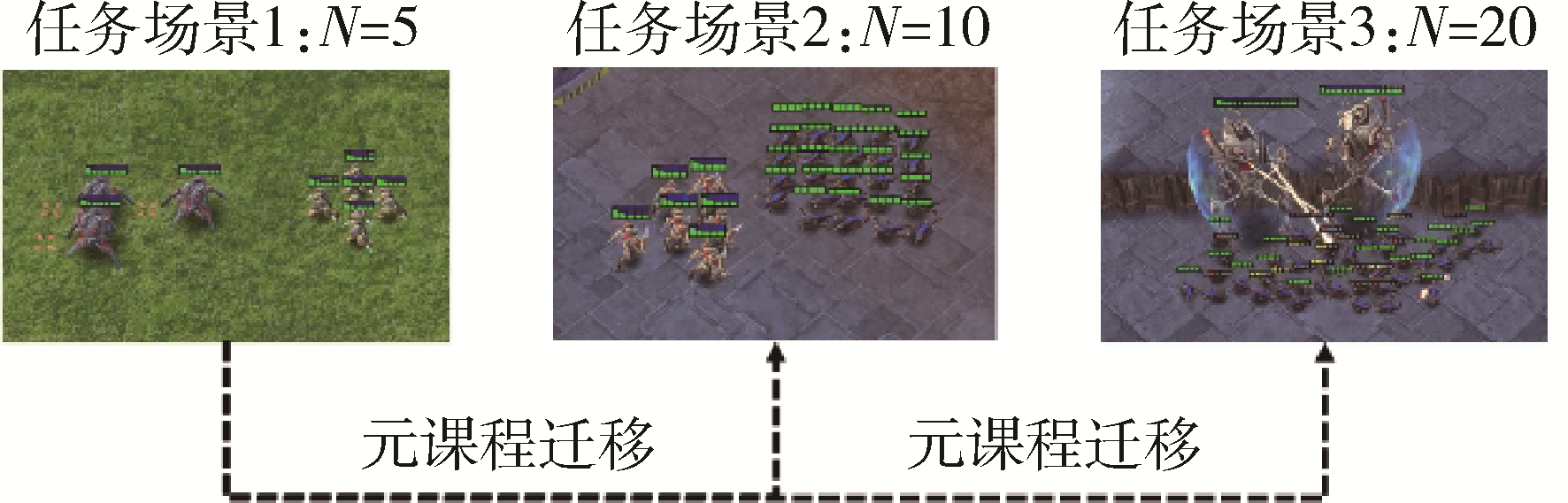
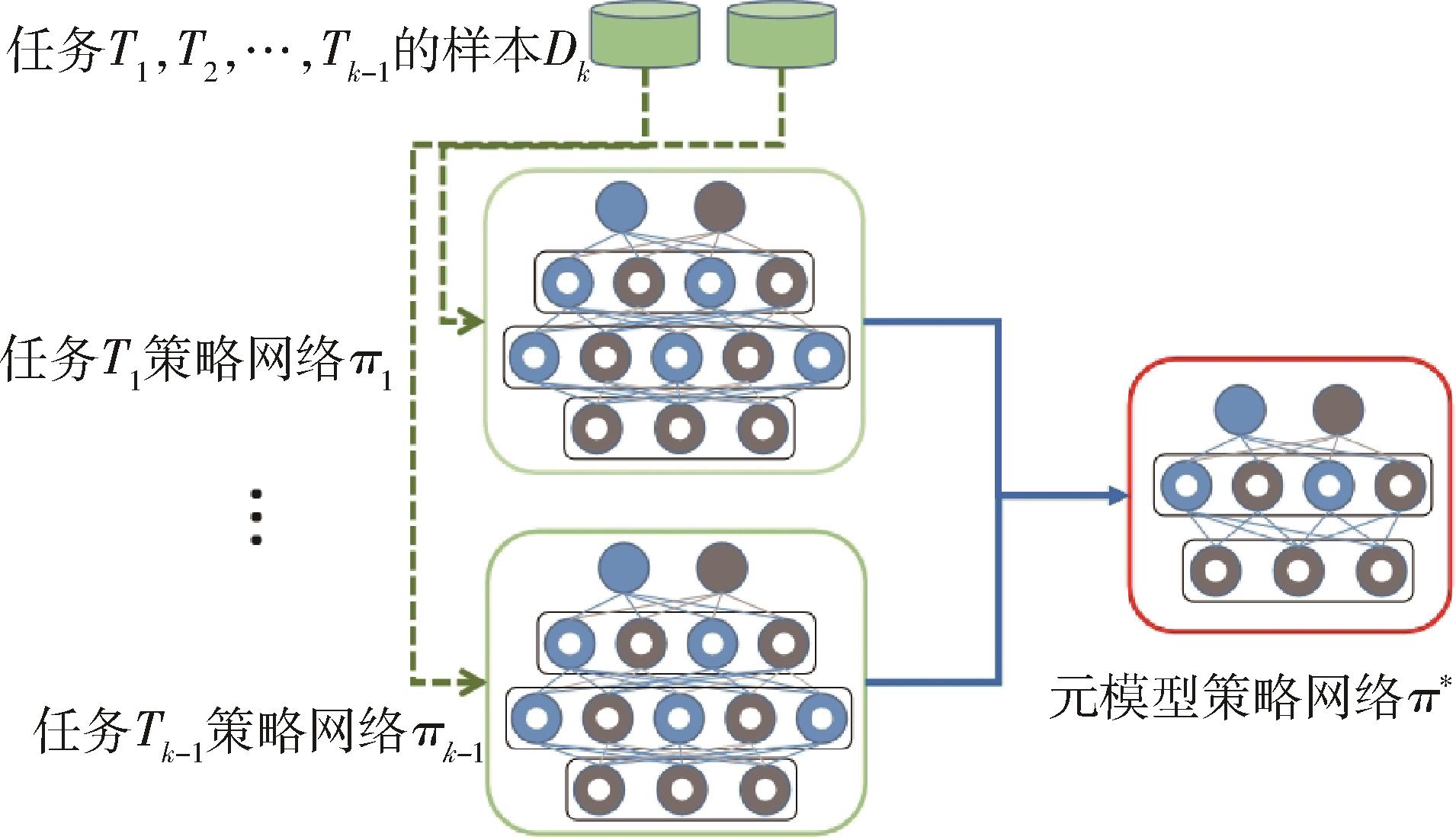
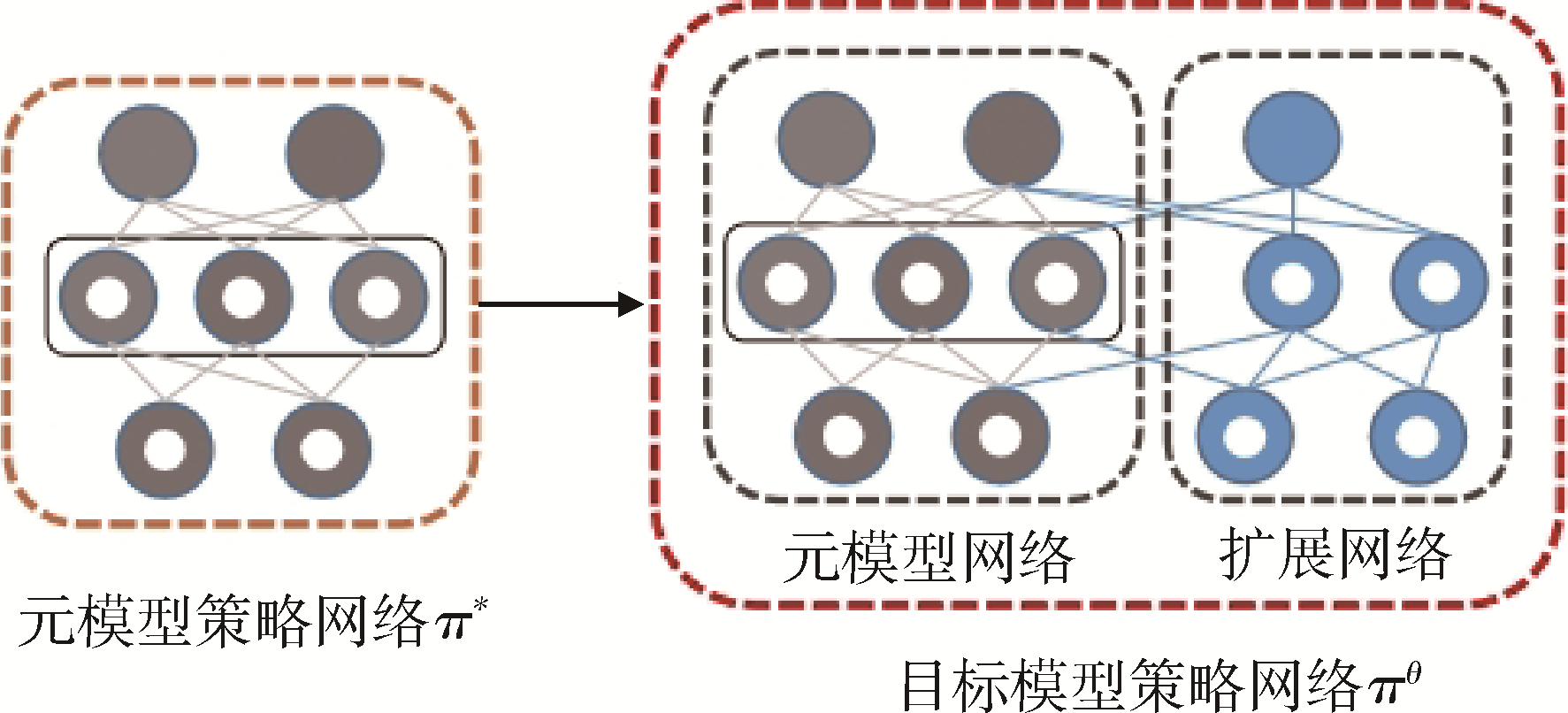
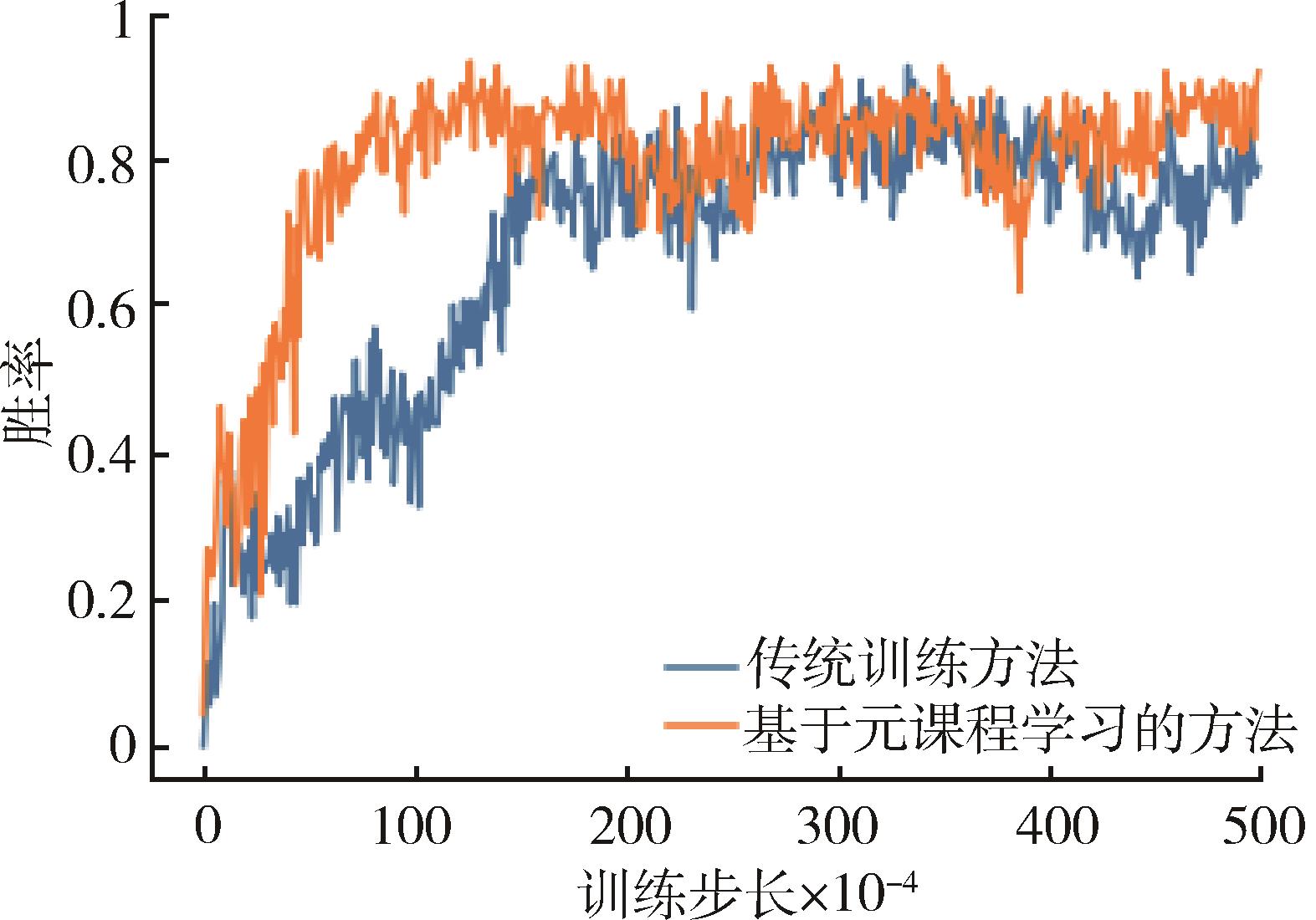
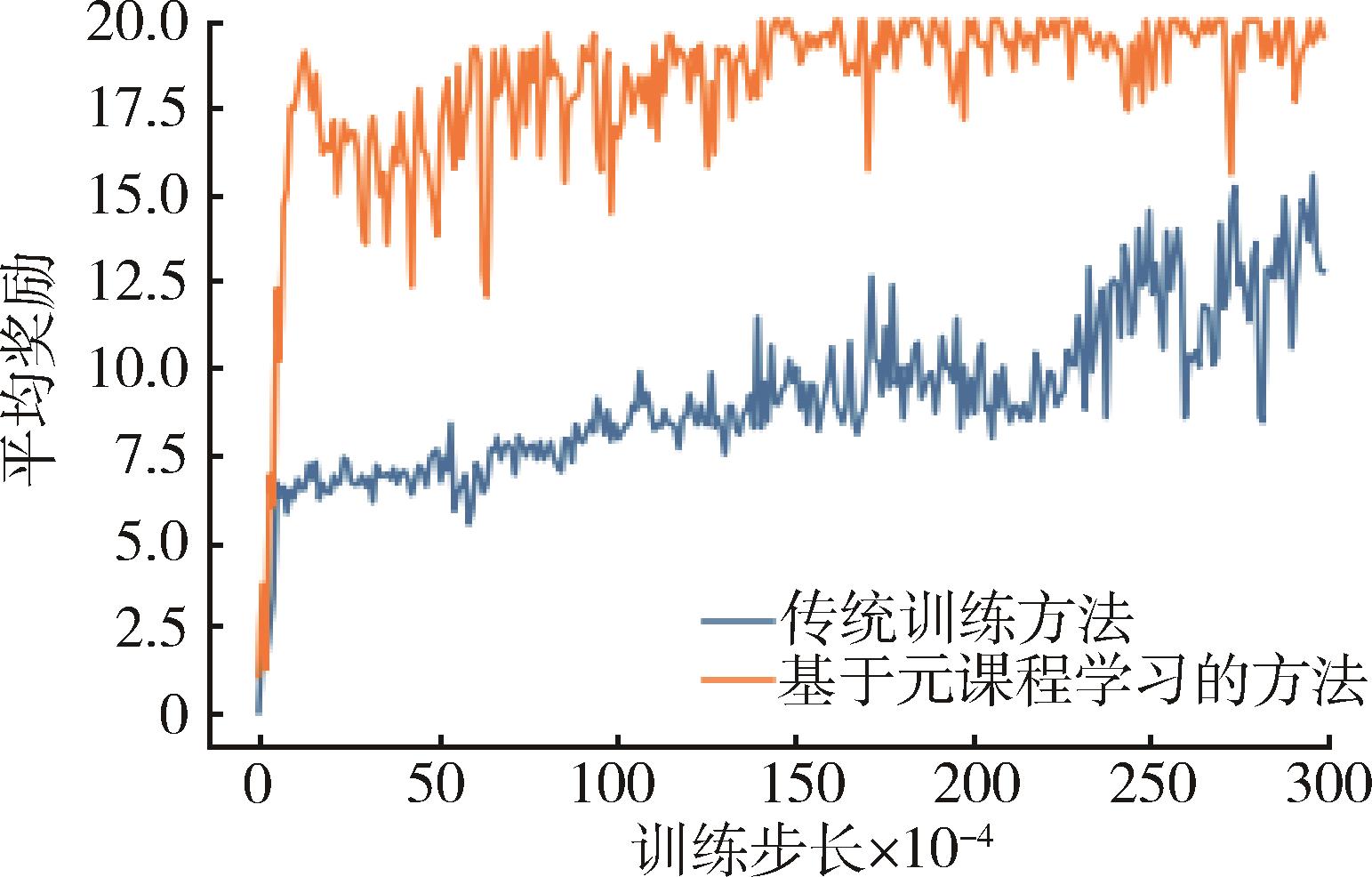
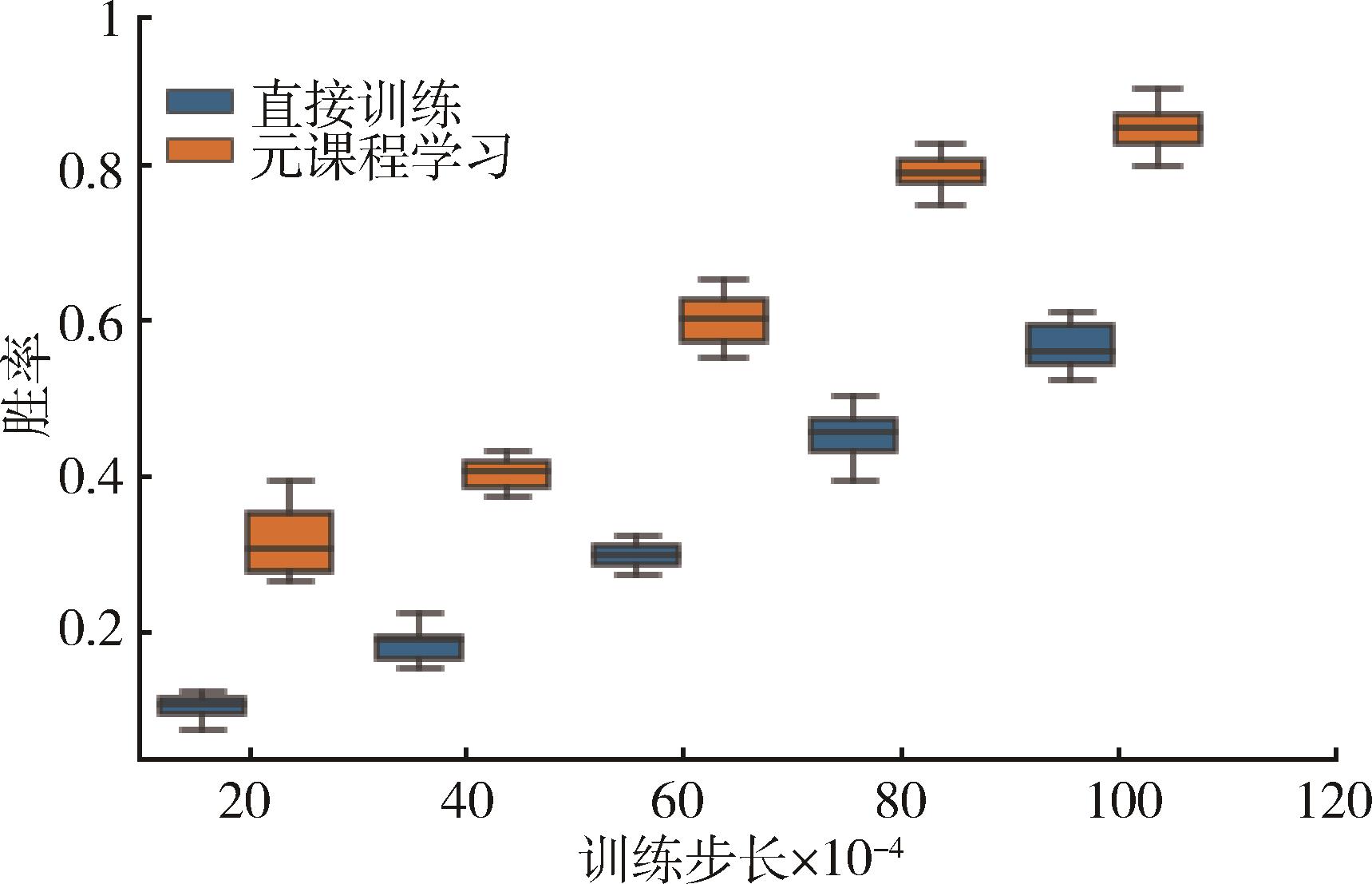
多智能体协同博弈具有实时及动作连续性、非完全信息博弈、庞大的搜索空间、多复杂任务和时间空间推理等特点,是当前人工智能领域极具挑战的难题之一。针对大规模多智能体强化学习训练时间长、难以收敛等问题,提出了一种基于Actor-Critic的多智能体强化学习协同博弈框架,利用元课程强化学习方法对小规模场景进行基础课程元模型提取,并且基于课程学习向大规模场景进行模型迁移,在元模型基础上继续进行训练,扩展元模型策略网络,最终得到较优协同博弈策略。在《星际争霸Ⅱ》平台上进行仿真实验,结果表明:基于元课程强化学习的多智能体协同博弈技术可有效地加速其训练过程,相较于传统训练方法可以在较短时间内达到较高的胜率,训练速度提升约40%,该方法可有效支撑多智能体协同博弈策略的高效生成,为低资源下的强化学习高效训练奠定理论基础。
中图分类号: