Modern Defense Technology ›› 2026, Vol. 54 ›› Issue (3): 93-103.DOI: 10.3969/j.issn.1009-086x.2026.03.009
• PAPERS • Previous Articles Next Articles
Tongyu SHI1, Hao WANG2, Youkun WANG1, Maolong LÜ1
Received:2025-05-28
Revised:2025-08-21
Online:2026-06-28
Published:2026-07-03
Contact:
Maolong Lü
通讯作者:
吕茂隆
作者简介:史桐雨(2004-),男,河南南阳人。本科生,研究方向为有人无人协同空战。
CLC Number:
Tongyu SHI, Hao WANG, Youkun WANG, Maolong LÜ. Simulation of Game-Theoretic Decision-Making for Beyond-Visual-Range Combat with UCAVs[J]. Modern Defense Technology, 2026, 54(3): 93-103.
史桐雨, 王昊, 王酉琨, 吕茂隆. 无人作战飞机超视距空战博弈对抗决策仿真[J]. 现代防御技术, 2026, 54(3): 93-103.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.xdfyjs.cn/EN/10.3969/j.issn.1009-086x.2026.03.009
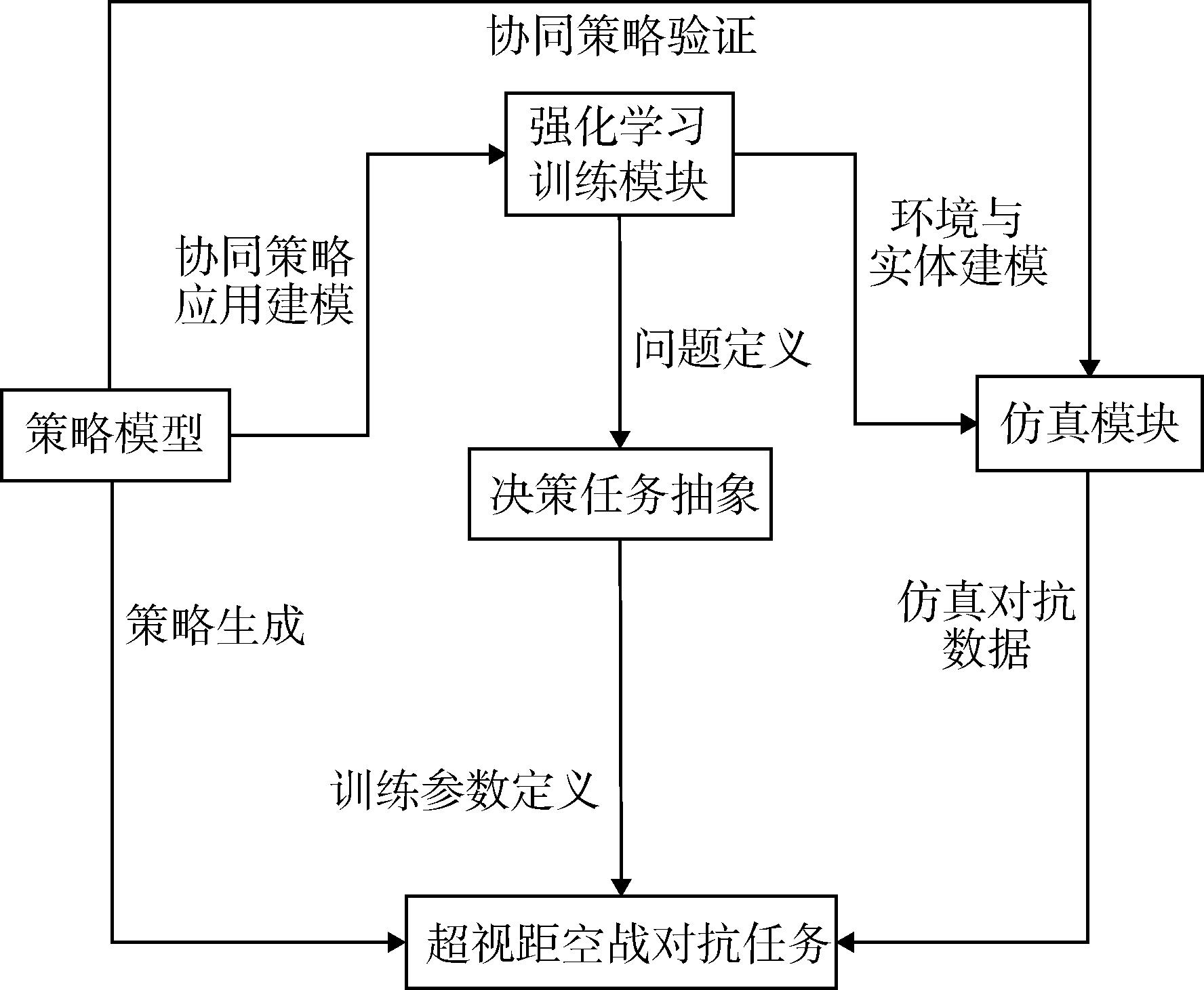
Fig. 1 Flowchart for generating task strategies of one-on-oneair combat cooperative confrontation
| A | 介绍 | A | 介绍 |
|---|---|---|---|
| a1 | 直飞加速 | a7 | 半滚倒转防御 |
| a2 | 爬升 | a8 | 大回环防御 |
| a3 | 目标位置追踪 | a9 | 90°侧转机动 |
| a4 | 高强度回旋 | a10 | 置尾机动 |
| a5 | 低强度回旋 | a11 | 策略偏置 |
| a6 | 高角度追踪 | a12 | 蛇形机动 |
Table 1 Tactical action based on the decision frame of beyond visual range air combat
| A | 介绍 | A | 介绍 |
|---|---|---|---|
| a1 | 直飞加速 | a7 | 半滚倒转防御 |
| a2 | 爬升 | a8 | 大回环防御 |
| a3 | 目标位置追踪 | a9 | 90°侧转机动 |
| a4 | 高强度回旋 | a10 | 置尾机动 |
| a5 | 低强度回旋 | a11 | 策略偏置 |
| a6 | 高角度追踪 | a12 | 蛇形机动 |
| Q | 介绍 |
|---|---|
| q1 | 远距离对峙(我方飞机距离敌方≥30 km) |
| q2 | 中远距离对峙(距离<30 km而≥10 km) |
| q3 | 中近距离对峙(距离<10 km而≥5 km) |
| q4 | 近距离对峙(距离<5 km) |
| q5 | 低能量状态(高度速度过低) |
Table 2 Typical situation of beyond visual range air combat decision frame
| Q | 介绍 |
|---|---|
| q1 | 远距离对峙(我方飞机距离敌方≥30 km) |
| q2 | 中远距离对峙(距离<30 km而≥10 km) |
| q3 | 中近距离对峙(距离<10 km而≥5 km) |
| q4 | 近距离对峙(距离<5 km) |
| q5 | 低能量状态(高度速度过低) |
| E | 介绍 | E | 介绍 |
|---|---|---|---|
| e1 | 天线偏置角变化 | e3 | 导弹锁定告警 |
| e2 | 能量评估 | e4 | 高度速度评估 |
Table 3 Typical events of the decision frame of beyond visual range air combat
| E | 介绍 | E | 介绍 |
|---|---|---|---|
| e1 | 天线偏置角变化 | e3 | 导弹锁定告警 |
| e2 | 能量评估 | e4 | 高度速度评估 |
| C | 介绍 |
|---|---|
| c1 | 我方飞机能量<目标能量的0.6倍 |
| c2 | 天线偏置角>70° |
| c3 | 天线偏置角≤15° |
| c4 | 天线偏置角>120°且进入角>150° |
| c5 | 距离<300 m且天线偏置角>60° |
| c6 | 天线偏置角>30° |
Table 4 Typical conditions of beyond visual range air combat decision frame
| C | 介绍 |
|---|---|
| c1 | 我方飞机能量<目标能量的0.6倍 |
| c2 | 天线偏置角>70° |
| c3 | 天线偏置角≤15° |
| c4 | 天线偏置角>120°且进入角>150° |
| c5 | 距离<300 m且天线偏置角>60° |
| c6 | 天线偏置角>30° |
| Rule | Q | E | C | A | Q' |
|---|---|---|---|---|---|
| Rule1 | q1 | e1 | c2 | a3 | q2 |
| Rule2 | q1 | e1 | ¬c2 | a11 | q1 |
| Rule3 | q2 | e1 | c3 | a12 | q3 |
| Rule4 | q2 | — | — | a3 | q2 |
| Rule5 | q3 | e2 | c1 | a1 | q3 |
| Rule6 | q3 | e1 | c4 | a4 | q4 |
| Rule7 | q3 | e1 | c6 | a5 | q4 |
| Rule8 | q3 | e3 | — | a9 | q4 |
| Rule9 | q3 | — | — | a3 | q3 |
| Rule10 | q4 | e1 | c6 | a3 | q4 |
| Rule11 | q4 | e1 | c4 | a7 | q4 |
| Rule12 | q4 | e1 | ¬c4⋁¬c5⋁¬c6 | a6 | q4 |
| Rule13 | q4 | e1 | c5 | a8 | q4 |
| Rule14 | q4 | e3 | — | a10 | q4 |
| Rule15 | q4 | e4 | — | a2 | q1 |
| Rule16 | q5 | — | — | a2 | q1 |
Table 5 Decision frame rule set for beyond visual range air combat
| Rule | Q | E | C | A | Q' |
|---|---|---|---|---|---|
| Rule1 | q1 | e1 | c2 | a3 | q2 |
| Rule2 | q1 | e1 | ¬c2 | a11 | q1 |
| Rule3 | q2 | e1 | c3 | a12 | q3 |
| Rule4 | q2 | — | — | a3 | q2 |
| Rule5 | q3 | e2 | c1 | a1 | q3 |
| Rule6 | q3 | e1 | c4 | a4 | q4 |
| Rule7 | q3 | e1 | c6 | a5 | q4 |
| Rule8 | q3 | e3 | — | a9 | q4 |
| Rule9 | q3 | — | — | a3 | q3 |
| Rule10 | q4 | e1 | c6 | a3 | q4 |
| Rule11 | q4 | e1 | c4 | a7 | q4 |
| Rule12 | q4 | e1 | ¬c4⋁¬c5⋁¬c6 | a6 | q4 |
| Rule13 | q4 | e1 | c5 | a8 | q4 |
| Rule14 | q4 | e3 | — | a10 | q4 |
| Rule15 | q4 | e4 | — | a2 | q1 |
| Rule16 | q5 | — | — | a2 | q1 |
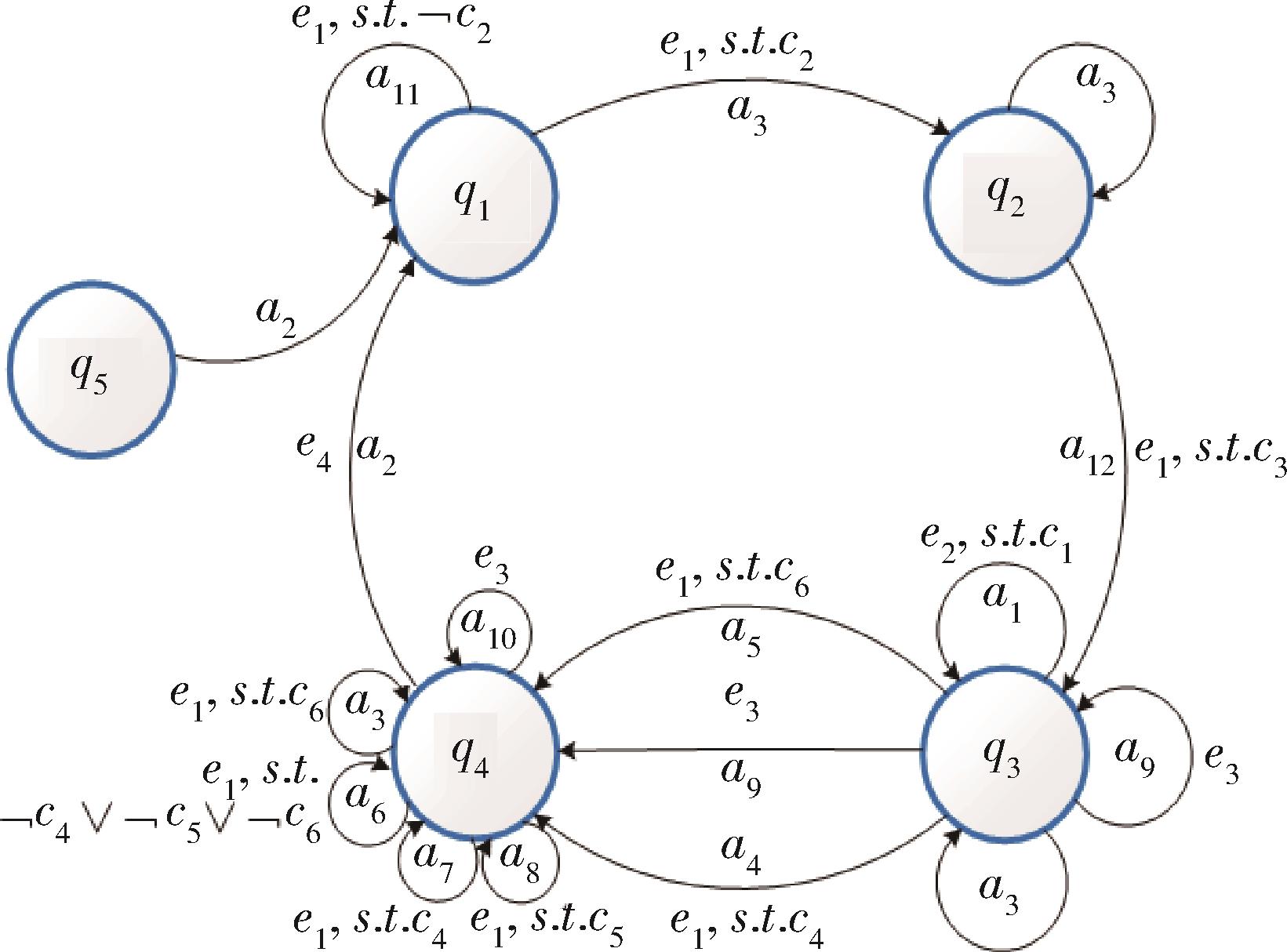
Fig. 2 Situation transformation diagram underthe framework of decision logic
| 参数名称 | 数值 |
|---|---|
| 初始距离/km | 100~120 |
| 初始高度/km | 8~10 |
| 初始Ma数 | 1.0~1.2 |
| 初始方位角/(°) | 150~180 |
| 挂载近距弹数量 | 2 |
| 挂载中距弹数量 | 3 |
Table 6 Initialization data of simulation experiment environment
| 参数名称 | 数值 |
|---|---|
| 初始距离/km | 100~120 |
| 初始高度/km | 8~10 |
| 初始Ma数 | 1.0~1.2 |
| 初始方位角/(°) | 150~180 |
| 挂载近距弹数量 | 2 |
| 挂载中距弹数量 | 3 |
| 类型 | 中距弹发射数 | 近距弹发射数 | 胜率/% |
|---|---|---|---|
| 红方 | 2.7 | 1.8 | 17 |
| 蓝方 | 2.5 | 1.5 | 71 |
Table 7 Average arithmetic data of simulation experiment
| 类型 | 中距弹发射数 | 近距弹发射数 | 胜率/% |
|---|---|---|---|
| 红方 | 2.7 | 1.8 | 17 |
| 蓝方 | 2.5 | 1.5 | 71 |
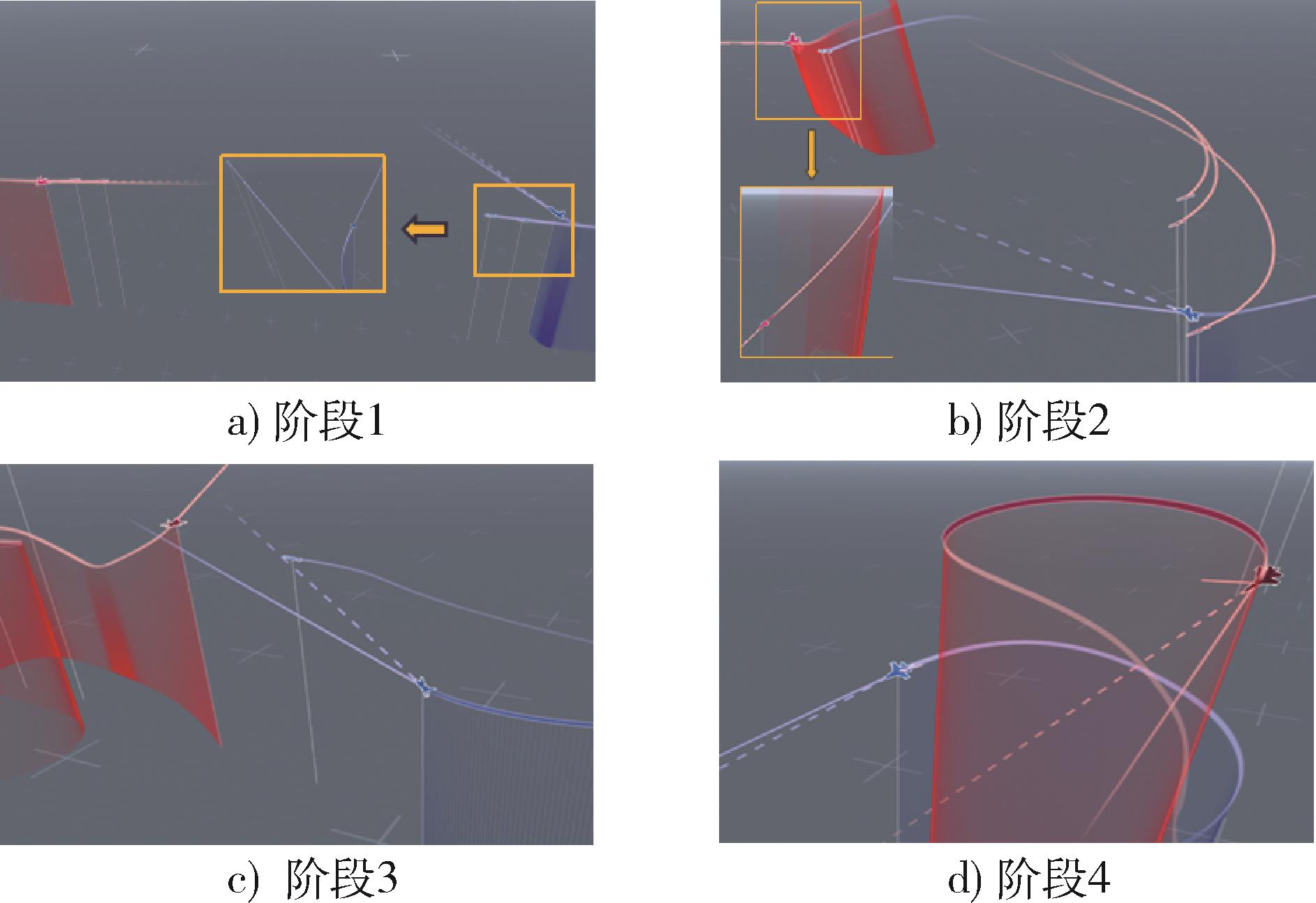
Fig. 3 Example of beyond visual range air combat simulation contest
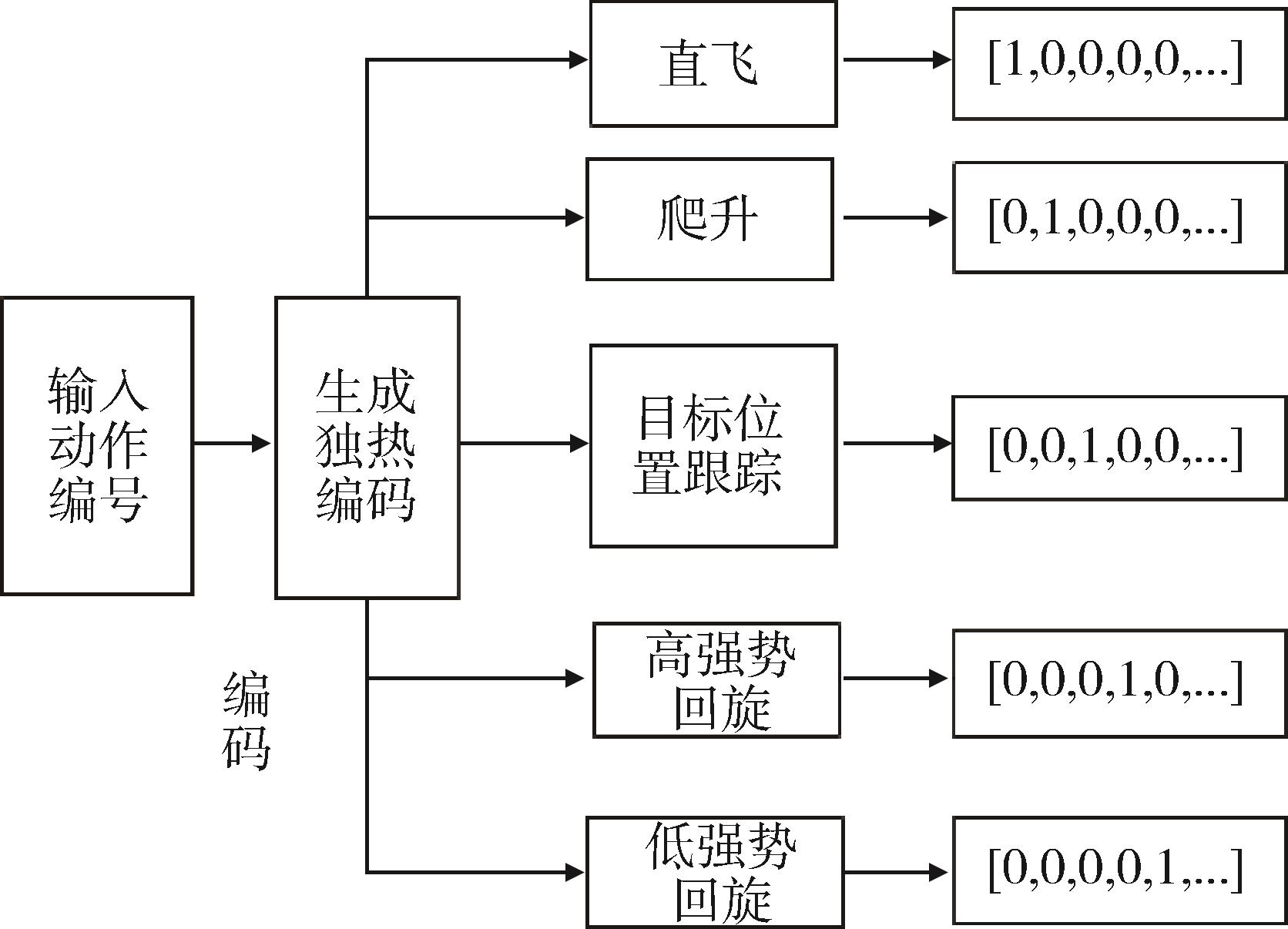
Fig. 4 Process diagram for converting action numbers to one-hot encoding
| 参数 | 介绍 |
|---|---|
| 我方战机三维坐标 | |
| 我方战机速度矢量 | |
| 敌方战机三维坐标 | |
| 敌方战机速度矢量 | |
| 敌我距离矢量 | |
| 天线偏置角 | |
| 尾后角 | |
| 我与敌导弹距离矢量 |
Table 8 State space input information parameters
| 参数 | 介绍 |
|---|---|
| 我方战机三维坐标 | |
| 我方战机速度矢量 | |
| 敌方战机三维坐标 | |
| 敌方战机速度矢量 | |
| 敌我距离矢量 | |
| 天线偏置角 | |
| 尾后角 | |
| 我与敌导弹距离矢量 |
| A | 介绍 | A | 介绍 |
|---|---|---|---|
| a1 | 直飞加速 | a6 | 高角度追踪 |
| a2 | 爬升 | a7 | 半滚倒转防御 |
| a3 | 目标位置追踪 | a8 | 大回环防御 |
| a4 | 高强势回旋 | a9 | 蛇形机动 |
| a5 | 低强势回旋 | a10 | 三九机动 |
Table 9 Action space tactical action set
| A | 介绍 | A | 介绍 |
|---|---|---|---|
| a1 | 直飞加速 | a6 | 高角度追踪 |
| a2 | 爬升 | a7 | 半滚倒转防御 |
| a3 | 目标位置追踪 | a8 | 大回环防御 |
| a4 | 高强势回旋 | a9 | 蛇形机动 |
| a5 | 低强势回旋 | a10 | 三九机动 |
| 奖励类型 | 事件 | 取值 |
|---|---|---|
| 回合奖励 | 胜 | 10 |
| 平 | 0 | |
| 负 | -8 | |
| 击落 | 2 | |
| 被击落 | -2 | |
| 关键事件奖励 | 锁定 | 0.05 |
| 被锁定 | -0.05 | |
| 规避导弹 | 1 | |
| 导弹未命中 | -1 | |
| 优势态势奖励 | 能量优势 | 0.05 |
| 高度优势 | 0.04 | |
| 角度优势 | 0.03 | |
| 高度保护 | 安全飞行 | 0.005 |
| 危险飞行 | -0.5 | |
| 单步奖励 | 每步 | -0.01 |
Table 10 Reward function event and value design
| 奖励类型 | 事件 | 取值 |
|---|---|---|
| 回合奖励 | 胜 | 10 |
| 平 | 0 | |
| 负 | -8 | |
| 击落 | 2 | |
| 被击落 | -2 | |
| 关键事件奖励 | 锁定 | 0.05 |
| 被锁定 | -0.05 | |
| 规避导弹 | 1 | |
| 导弹未命中 | -1 | |
| 优势态势奖励 | 能量优势 | 0.05 |
| 高度优势 | 0.04 | |
| 角度优势 | 0.03 | |
| 高度保护 | 安全飞行 | 0.005 |
| 危险飞行 | -0.5 | |
| 单步奖励 | 每步 | -0.01 |
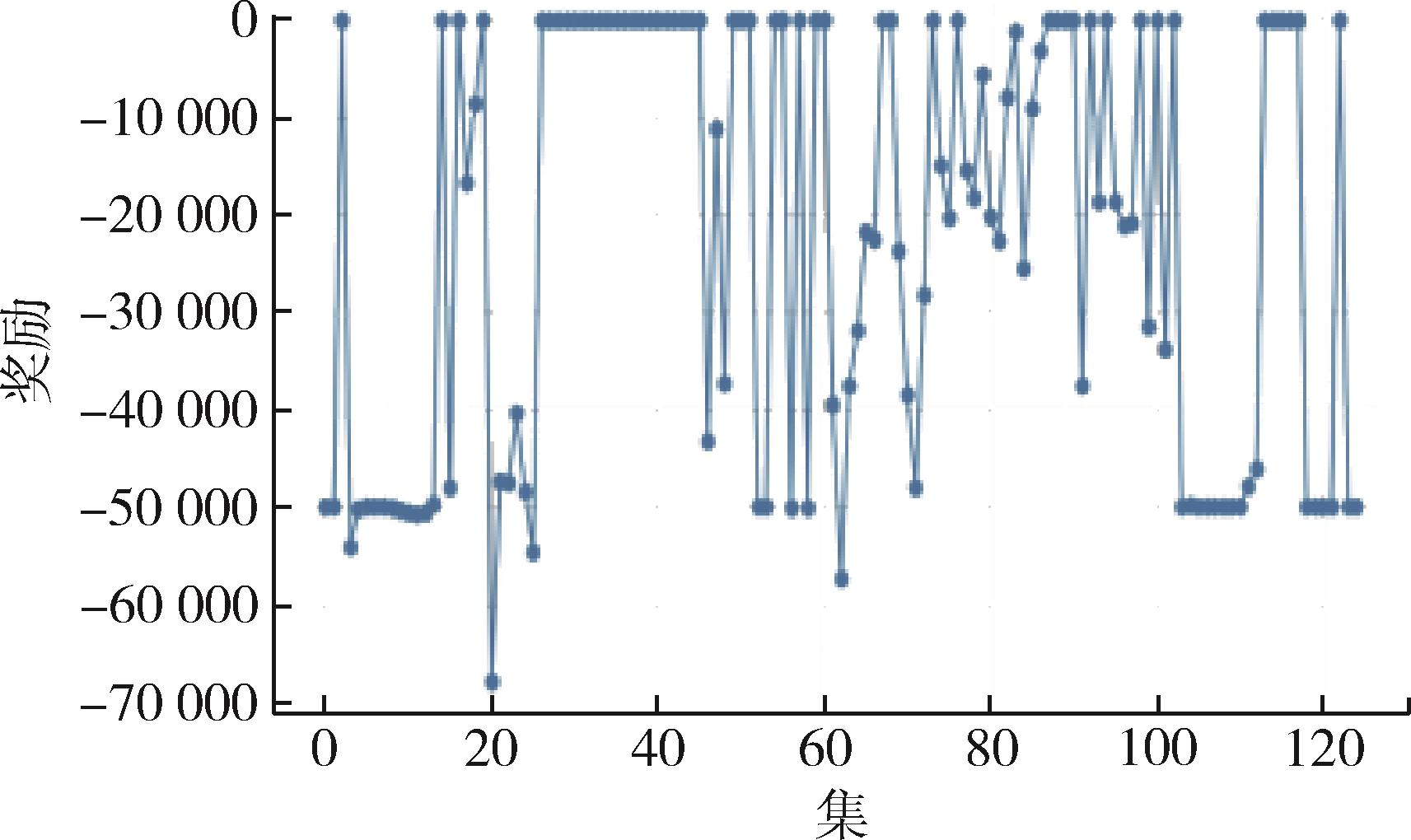
Fig. 5 Line chart of the changes in the initial training reward value
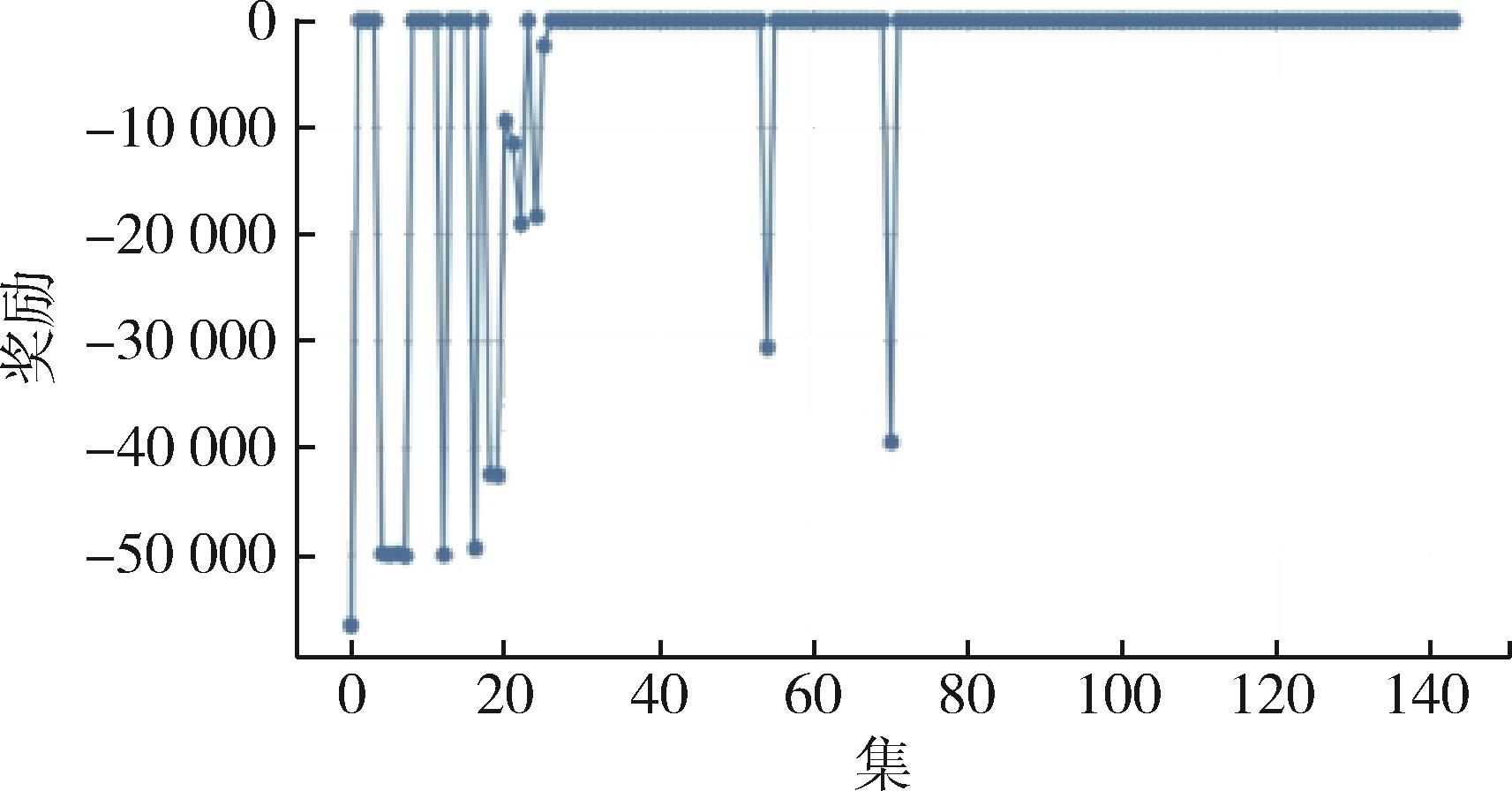
Fig. 6 Line chart showing the changes in reward values after training of adversarial strategy optimization

Fig. 7 Escape with climb

Fig. 8 Straight flight after 39 maneuvering
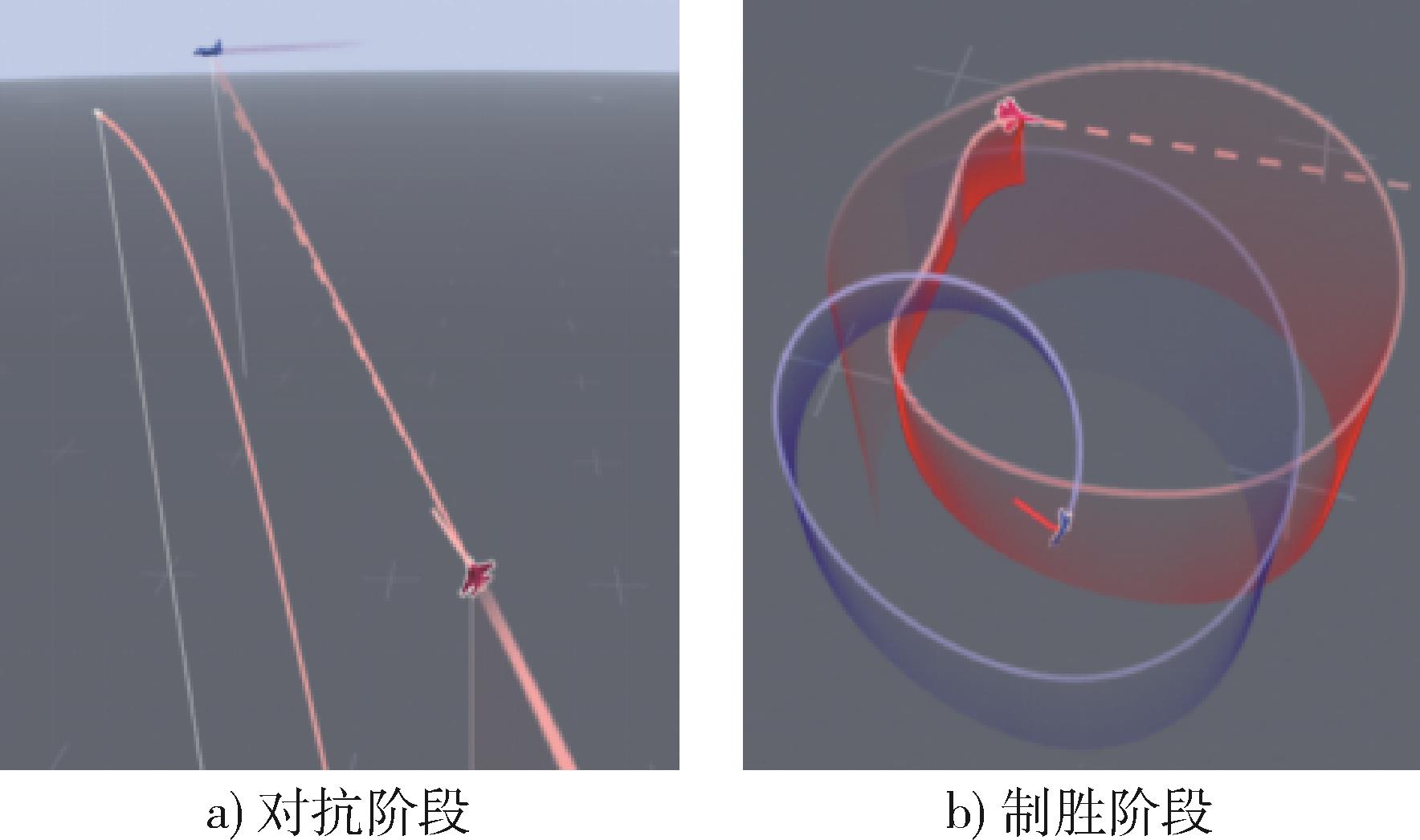
Fig. 9 Flowchart of the intelligent agent against bias strategy process

Fig. 10 Flow chart of the intelligent agent againstthe millstone strategy
| 评估维度 | 指标名称 | 规则集 | 状态机转移 |
|---|---|---|---|
| 对抗效能 | 胜率/% | 70.8 | 78.0 |
| 武器使用 | 单目标命中所需发射数 | 1.9 | 1.7 |
决策 能力 | 威胁识别准确率/% 战术响应延迟/ms | 91.1 240 | 92.7 233 |
| 鲁棒性 | 策略迁移成功率/% | 89 | 83 |
Table 11 Simulation experiment data statistics
| 评估维度 | 指标名称 | 规则集 | 状态机转移 |
|---|---|---|---|
| 对抗效能 | 胜率/% | 70.8 | 78.0 |
| 武器使用 | 单目标命中所需发射数 | 1.9 | 1.7 |
决策 能力 | 威胁识别准确率/% 战术响应延迟/ms | 91.1 240 | 92.7 233 |
| 鲁棒性 | 策略迁移成功率/% | 89 | 83 |
| [1] | 邓嘉宁. 无人机空战态势评估与机动决策方法研究[D]. 重庆: 重庆大学, 2023. |
| DENG Jianing. Research on UAV Air Combat Situation Assessment and Maneuver Decision Method[D]. Chongqing: Chongqing University, 2023. | |
| [2] | 车竞, 钱炜祺, 和争春. 基于矩阵博弈的两机攻防对抗空战仿真[J]. 飞行力学, 2015, 33(2): 173-177. |
| CHE Jing, QIAN Weiqi, HE Zhengchun. Attack-Defense Confrontation Simulation of Air Combat Based on Game-matrix Approach[J]. Flight Dynamics, 2015, 33(2): 173-177. | |
| [3] | 刘昊天, 王玉惠, 陈谋, 等. 基于对局迭代的无人机空战博弈研究[J]. 电光与控制, 2022, 29(2): 1-6. |
| LIU Haotian, WANG Yuhui, CHEN Mou, et al. UAV Air Combat Game Based on Iteration Method[J]. Electronics Optics & Control, 2022, 29(2): 1-6. | |
| [4] | 邓可, 彭宣淇, 周德云. 基于矩阵对策与遗传算法的无人机空战决策[J]. 火力与指挥控制, 2019, 44(12): 61-66, 71. |
| DENG Ke, PENG Xuanqi, ZHOU Deyun. Study on Air Combat Decision Method of UAV Based on Matrix Game and Genetic Algorithm[J]. Fire Control & Command Control, 2019, 44(12): 61-66, 71. | |
| [5] | 顾佼佼, 赵建军, 刘卫华. 基于博弈论及 Memetic算法求解的空战机动决策框架[J]. 电光与控制, 2015, 22(1): 20-23. |
| GU Jiaojiao, ZHAO Jianjun, LIU Weihua. Air Combat Maneuvering Decision Framework Based on Game Theory and Memetic Algorithm[J]. Electronics Optics & Control, 2015, 22(1): 20-23. | |
| [6] | 赵明明, 李彬, 王敏立. 多无人机超视距空战博弈策略研究[J]. 电光与控制, 2015, 22(4): 41-45. |
| ZHAO Mingming, LI Bin, WANG Minli. On Game Strategy for Multi-UAV Beyond-Visual-Range Air Combat[J]. Electronics Optics & Control, 2015, 22(4): 41-45. | |
| [7] | PARK H, LEE B Y, TAHK M J, et al. Differential Game Based Air Combat Maneuver Generation Using Scoring Function Matrix[J]. International Journal of Aeronautical and Space Sciences, 2016, 17(2): 204-213. |
| [8] | 邵将, 徐扬, 罗德林. 无人机多机协同对抗决策研究[J]. 信息与控制, 2018, 47(3): 347-354. |
| SHAO Jiang, XU Yang, LUO Delin. Cooperative Combat Decision-Making Research for Multi UAVs[J]. Information and Control, 2018, 47(3): 347-354. | |
| [9] | 谢季良, 马克茂. 基于微分对策的飞行器逃逸策略设计[J]. 航空兵器, 2025, 32(3): 57-63. |
| XIE Jiliang, MA Kemao. Differential Game Evading Strategy for a Flight Vehicle[J]. Aero Weaponry, 2025, 32(3): 57-63. | |
| [10] | HERRALA O, TERHO T, OLIVEIRA F. Risk-Averse Decision Strategies for Influence Diagrams Using Rooted Junction Trees[J]. Operations Research Letters, 2025, 61: 107308. |
| [11] | 周新民, 吴佳晖, 贾圣德, 等. 无人机空战决策技术研究进展[J]. 国防科技, 2021, 42(3): 33-41. |
| ZHOU Xinmin, WU Jiahui, JIA Shengde, et al. Progress in Research on Combat Decision-Making Technology in UAVs[J]. National Defense Technology, 2021, 42(3): 33-41. | |
| [12] | 刘昊天. 无人机空战对抗博弈决策研究[D]. 南京: 南京航空航天大学, 2022. |
| LIU Haotian. Research on Game Decision of UAV Air Combat Confrontation[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2022. | |
| [13] | 徐安, 郑万泽, 奚之飞, 等. 基于进化式决策树的超视距空战机动决策模型[J]. 现代防御技术, 2022, 50(6): 68-82. |
| XU An, ZHENG Wanze, XI Zhifei, et al. Improved Evolutionary Decision Tree for BVR Air Combat Decision Making[J]. Modern Defence Technology, 2022, 50(6): 68-82. | |
| [14] | 刘涛, 李艺海, 张奇. 基于零和博弈的近距空战机动决策方法研究[J]. 科技与创新, 2025(10): 18-22. |
| LIU Tao, LI Yihai, ZHANG Qi. Decision-Making Method for Close-Range Air Combat Based on Zero-Sum Game[J]. Science and Technology & Innovation, 2025(10): 18-22. | |
| [15] | 王捷, 刘俊辉, 陈昊, 等. 一种基于扰动补偿的机弹协同LOS主动防御制导律[J]. 现代防御技术, 2024, 52(2): 94-103. |
| WANG Jie, LIU Junhui, CHEN Hao, et al. Active Defense Line-of-Sight Guidance Law with Compensation of Unknown Disturbance for the Cooperation of Aircraft and Interceptor[J]. Modern Defence Technology, 2024, 52(2): 94-103. | |
| [16] | 卿朝进, 赵桂毅, 刘宇畅, 等. 专家校验与人工蜂群算法结合的地面防空设备部署策略[J]. 电子信息对抗技术, 2025, 40(3): 75-84. |
| QING Zhaojin, ZHAO Guiyi, LIU Yuchang, et al. Deployment Strategy of Ground Air Defense Equipment Combining Expert Verification and Artificial Bee Colony Algorithm[J]. Electronic Information Warfare Technology, 2025, 40(3): 75-84. | |
| [17] | 任桢, 韩兵, 蔡慧敏. 基于多专家决策相关滤波的光谱目标跟踪算法[C]∥第十三届中国指挥控制大会论文集(下册)会议论文集. 北京: 中国指挥与控制学会, 2025: 328-332. |
| REN Zhen, HAN Bing, CAI Huimin. Spectral Target Tracking Algorithm Based on Multi-Expert Decision Correlation Filtering[C]∥Proceedings of the 13th China Conference on Command and Control. Beijing: Chinese Institute of Command and Control, 2025: 328-332. | |
| [18] | 梁复台, 周焰, 张晨浩, 等. 对抗条件下空中目标威胁评估方法[J]. 现代防御技术, 2024, 52(1): 147-154. |
| LIANG Futai, ZHOU Yan, ZHANG Chenhao, et al. Threat Assessment Method of Aerial Targets Under Confrontational Conditions[J]. Modern Defence Technology, 2024, 52(1): 147-154. | |
| [19] | 王忠禹, 徐晓鹏, 王东. 部分可观测条件下的策略迁移强化学习方法[J]. 现代防御技术, 2024, 52(2): 63-71. |
| WANG Zhongyu, XU Xiaopeng, WANG Dong. Policy Transfer Reinforcement Learning Method for Partially Observable Conditions[J]. Modern Defence Technology, 2024, 52(2): 63-71. |
| [1] | Haozhe QI, Mingfa ZHENG, Xiaorong HU, Nan YANG. Reinforcement Learning-Based Cooperative Trajectory Planning for Unmanned Combat Aerial Vehicles and Decoy UAVs [J]. Modern Defense Technology, 2026, 54(3): 71-81. |
| [2] | Xiaowen CHEN, Qing YANG, Junmin WANG. Survival Strategies for Unmanned Aerial Vehicle Systems Under Strong Denial Conditions [J]. Modern Defense Technology, 2026, 54(1): 1-13. |
| [3] | Xucheng CHANG, Xinhui ZHANG, Shuailong DANG, Feng ZHU, Jingyu WANG, Gaohan XU. Research on UAV Path Planning Based on an Improved A*-DWA Hierarchical Fusion Algorithm [J]. Modern Defense Technology, 2026, 54(1): 14-29. |
| [4] | Wei GUO, Yuan CHANG, Fang CHENG, Qingyun WANG, Chong WANG. Research and Reflection on Intelligent Guidance Based on Deep Reinforcement Learning [J]. Modern Defense Technology, 2026, 54(1): 73-84. |
| [5] | Xuejian FENG, Yifei LI, Yiqi TONG, Yanjin ZHANG. An Improved ARA*-Based Path Planning Algorithm for UAV [J]. Modern Defense Technology, 2025, 53(6): 101-110. |
| [6] | Junbiao ZHANG, Jing WU, Fei ZHAO, Li FANG. Application and Enlightenment of UAV in the Russia-Ukraine Conflict [J]. Modern Defense Technology, 2025, 53(6): 37-45. |
| [7] | Yaoluo HUI, Bo XU, Xiumin LI, Luyao ZANG, Liu LIU. A Review of Development of Intelligent Penetration Technology for Missile Cluster [J]. Modern Defense Technology, 2025, 53(6): 69-81. |
| [8] | Hongxin LI, Xiaojia ZHAO, Zhenxin HONG, Lifeng GAN, Guoxu FENG. Optimization Method for Cost Reduction in Design and Development of Unmanned Aerial Vehicles [J]. Modern Defense Technology, 2025, 53(5): 11-20. |
| [9] | Zhenhan WEI, Hui TANG, Yu YANG, Zhihong LIAO, Qihui LAI, Chen LU. Multi-UAV Path Planning Based on Reinforcement Learning [J]. Modern Defense Technology, 2025, 53(5): 136-144. |
| [10] | Qing CHEN, Chun ZHOU, Xinjun LIU, Ruijun LUO. Stationary Finite-time Formation Control of UAVs Under Bearing Constraints [J]. Modern Defense Technology, 2025, 53(5): 197-205. |
| [11] | Nan LIU. UAV Swarm Threat Assessment Method Based on Improved PROMETHEE [J]. Modern Defense Technology, 2025, 53(5): 92-98. |
| [12] | Shixiang YAN, Haijun LIU. Sensor-Weapon-Target Assignment Method Based on Deep Reinforcement Learning [J]. Modern Defense Technology, 2025, 53(4): 10-17. |
| [13] | Zonghui WANG, Yunjun YANG, Hongrui ZHAO, Jiaxiang ZHAO. Numerical Simulation of Tilting Wing and Rotor UAV During Transition Flight [J]. Modern Defense Technology, 2024, 52(3): 9-19. |
| [14] | Jingyu HE, Jizheng LIU, Zhichen YANG, Dongdong WANG, Ping OU. Development and Testing of Multi Rotor Unmanned Aerial Vehicle Noise Source Tracking and Positioning System [J]. Modern Defense Technology, 2024, 52(3): 1-8. |
| [15] | Zhongyu WANG, Xiaopeng XU, Dong WANG. Policy Transfer Reinforcement Learning Method for Partially Observable Conditions [J]. Modern Defense Technology, 2024, 52(2): 63-71. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||


