Modern Defense Technology ›› 2026, Vol. 54 ›› Issue (1): 73-84.DOI: 10.3969/j.issn.1009-086x.2026.01.007
• PAPERS • Previous Articles Next Articles
Wei GUO1, Yuan CHANG1, Fang CHENG2, Qingyun WANG2, Chong WANG1
Received:2024-12-25
Revised:2025-05-15
Online:2026-01-28
Published:2026-02-11
作者简介:郭威 (1996-),男,蒙古族,河北保定人。工程师,硕士,研究方向为人工智能、云计算和虚拟化。
CLC Number:
Wei GUO, Yuan CHANG, Fang CHENG, Qingyun WANG, Chong WANG. Research and Reflection on Intelligent Guidance Based on Deep Reinforcement Learning[J]. Modern Defense Technology, 2026, 54(1): 73-84.
郭威, 常远, 程芳, 王清云, 王冲. 基于深度强化学习智能制导的研究思考[J]. 现代防御技术, 2026, 54(1): 73-84.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.xdfyjs.cn/EN/10.3969/j.issn.1009-086x.2026.01.007
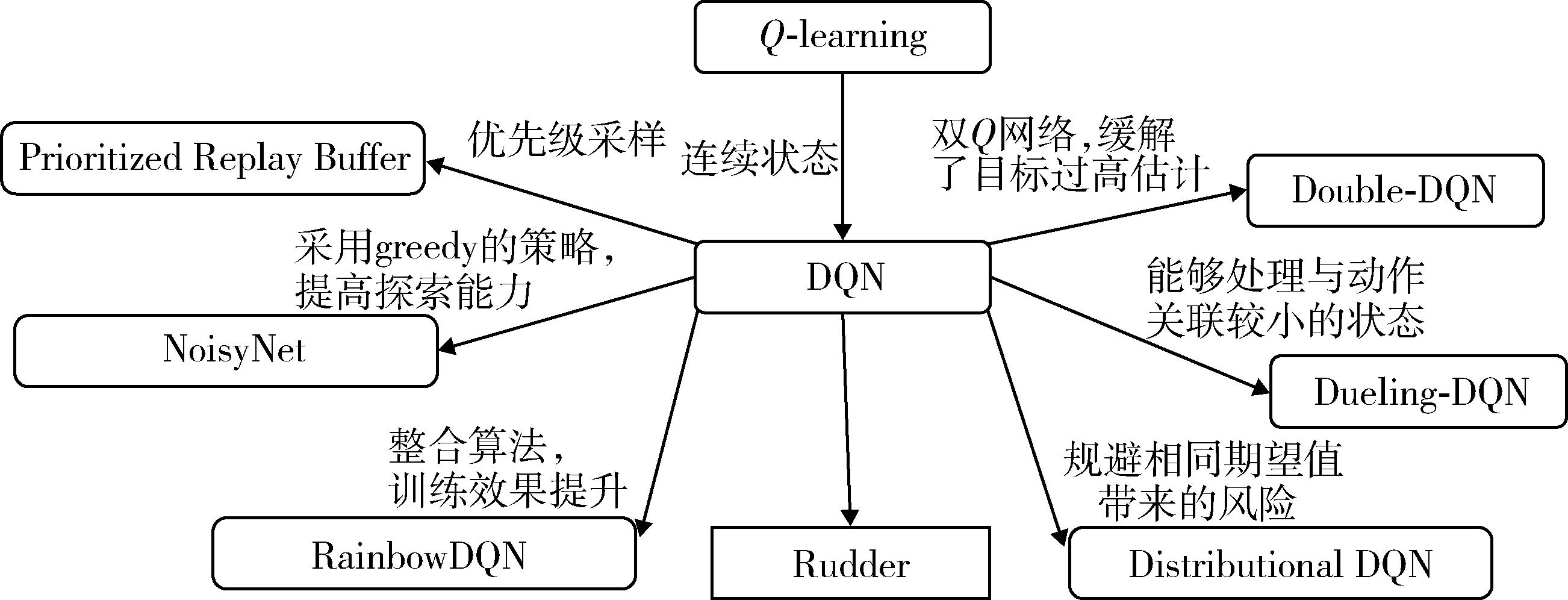
Fig. 1 DRL based on value function
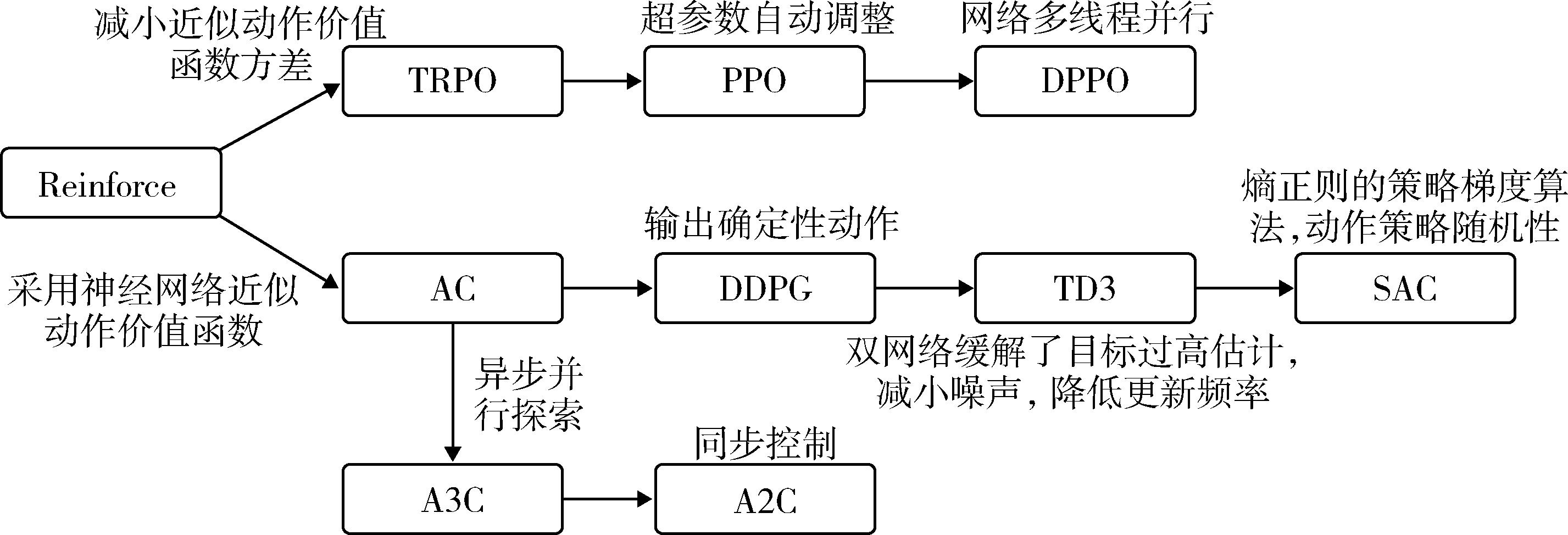
Fig. 2 DRL based on policy gradient
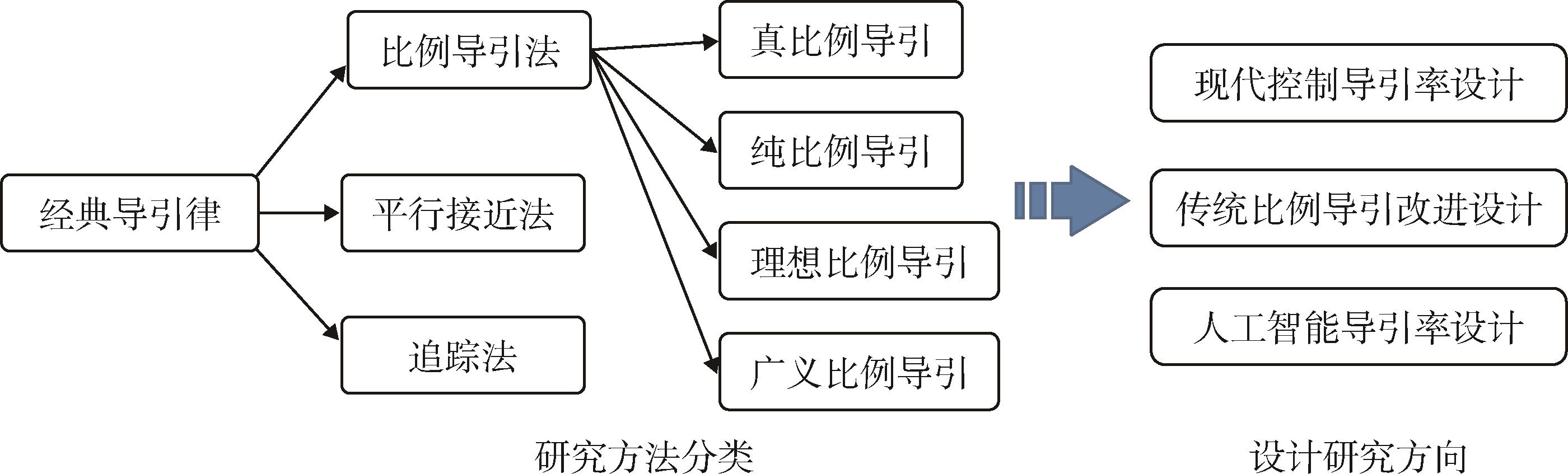
Fig. 3 Classification and research directions of classical guidance laws
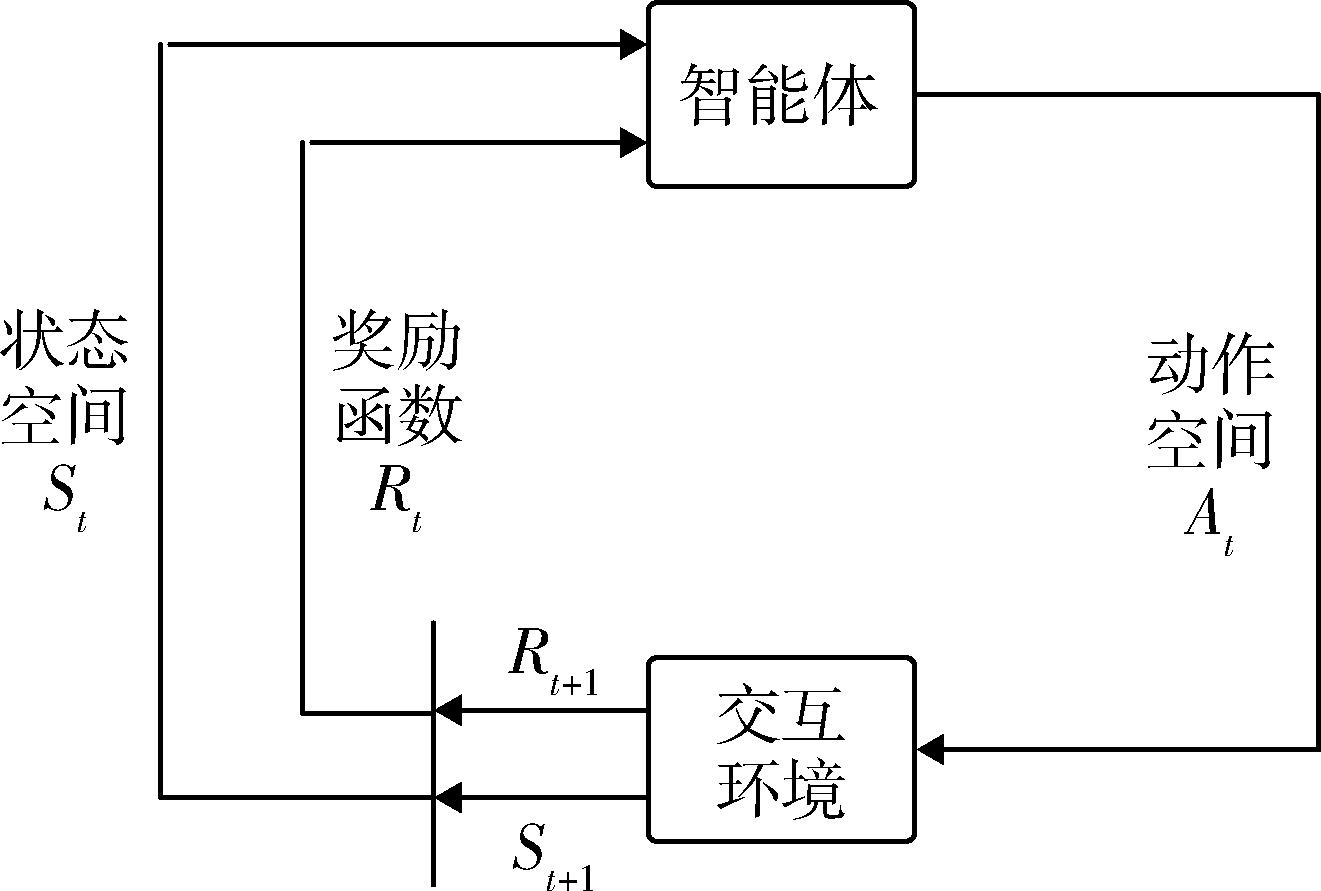
Fig. 4 Relationship of agent and interaitre enviornment
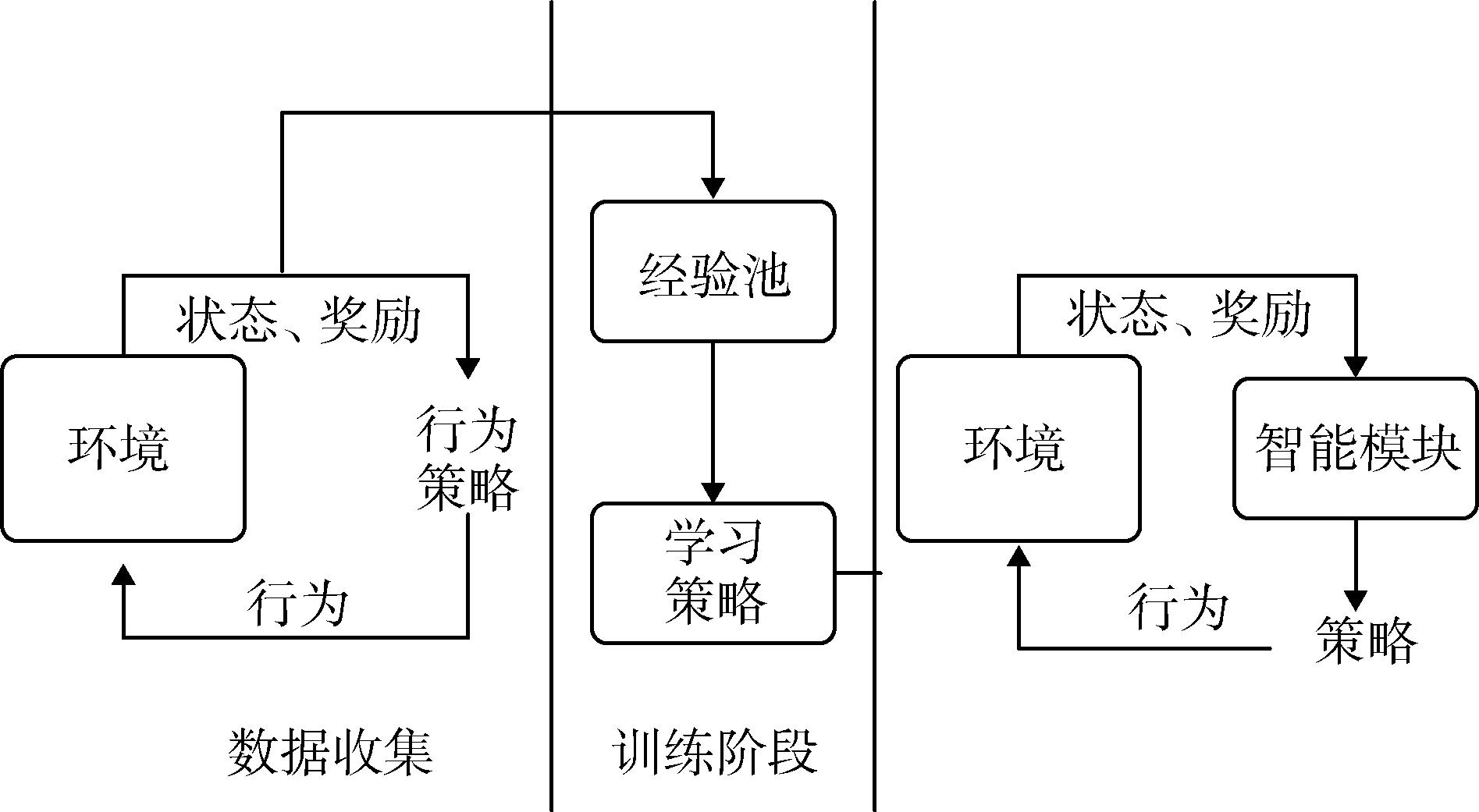
Fig. 5 Offline training model
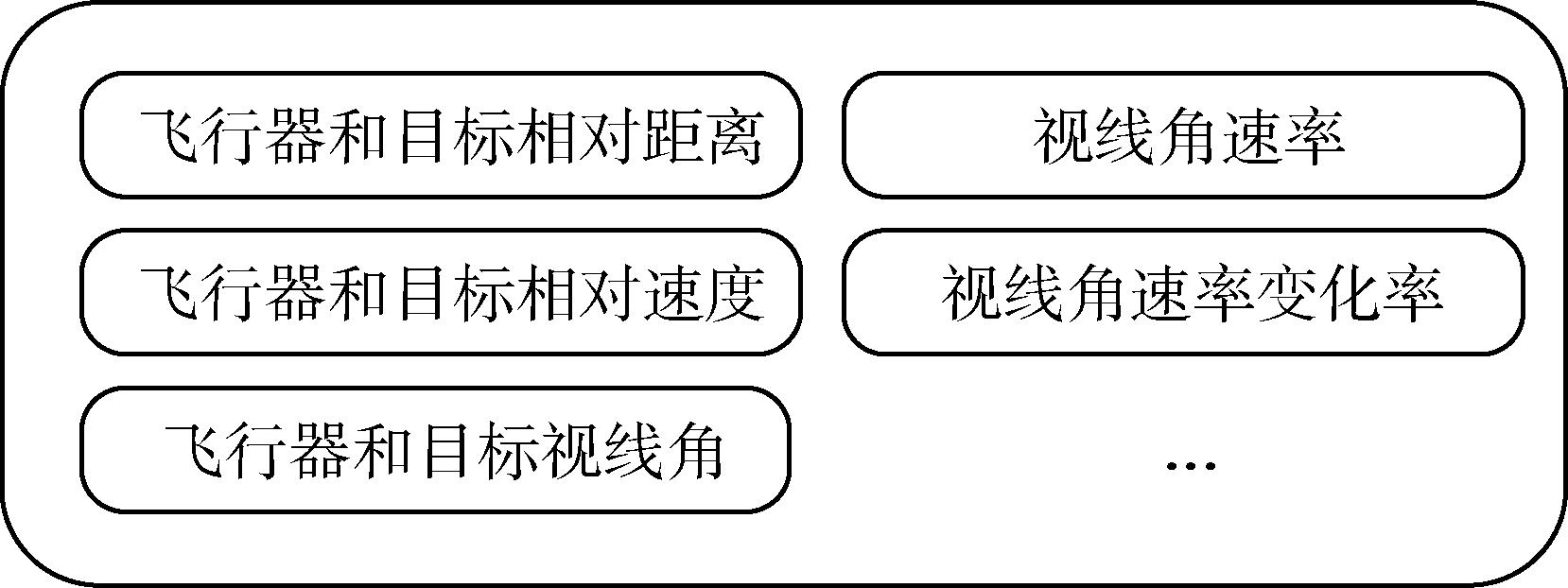
Fig. 6 State space parameters
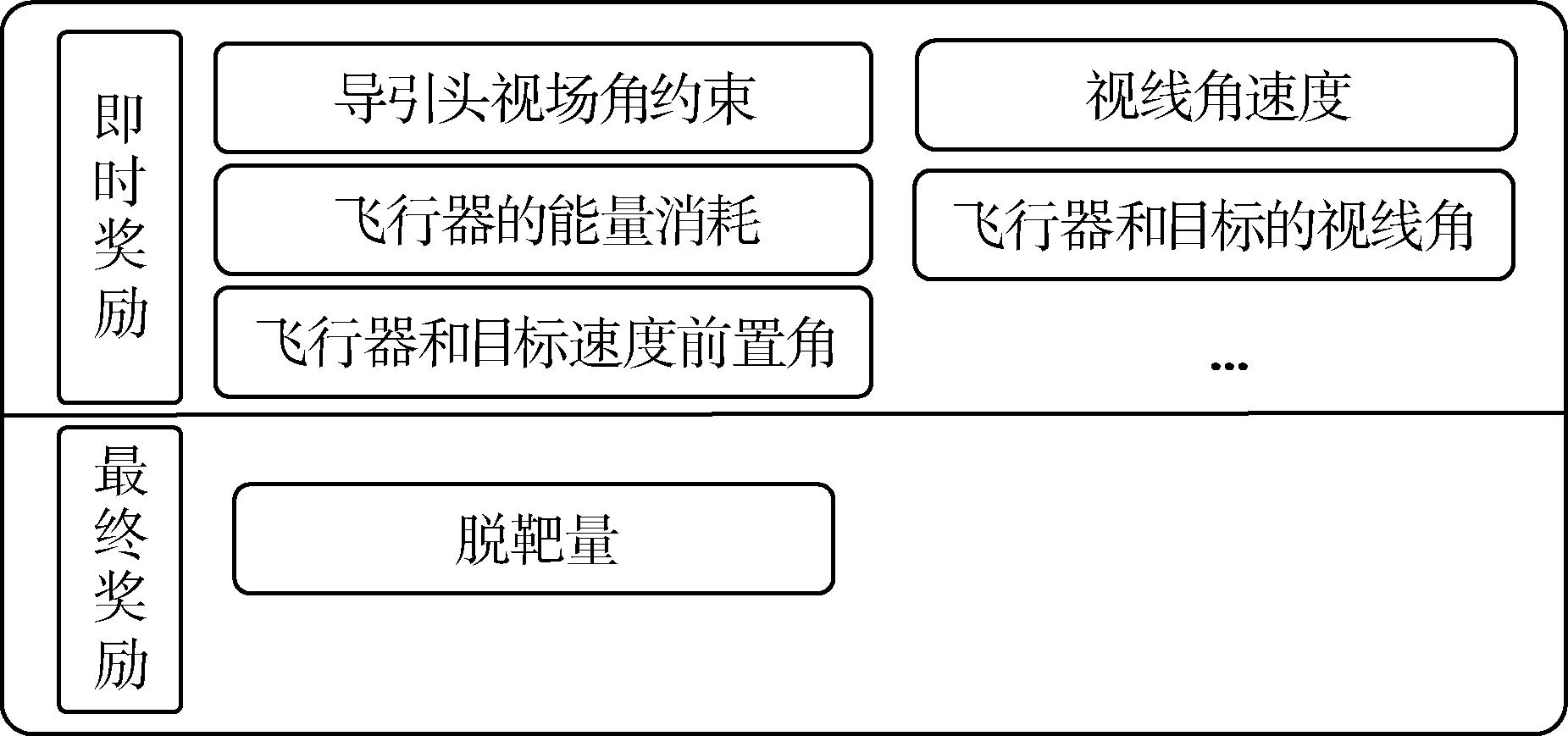
Fig. 7 Reward types
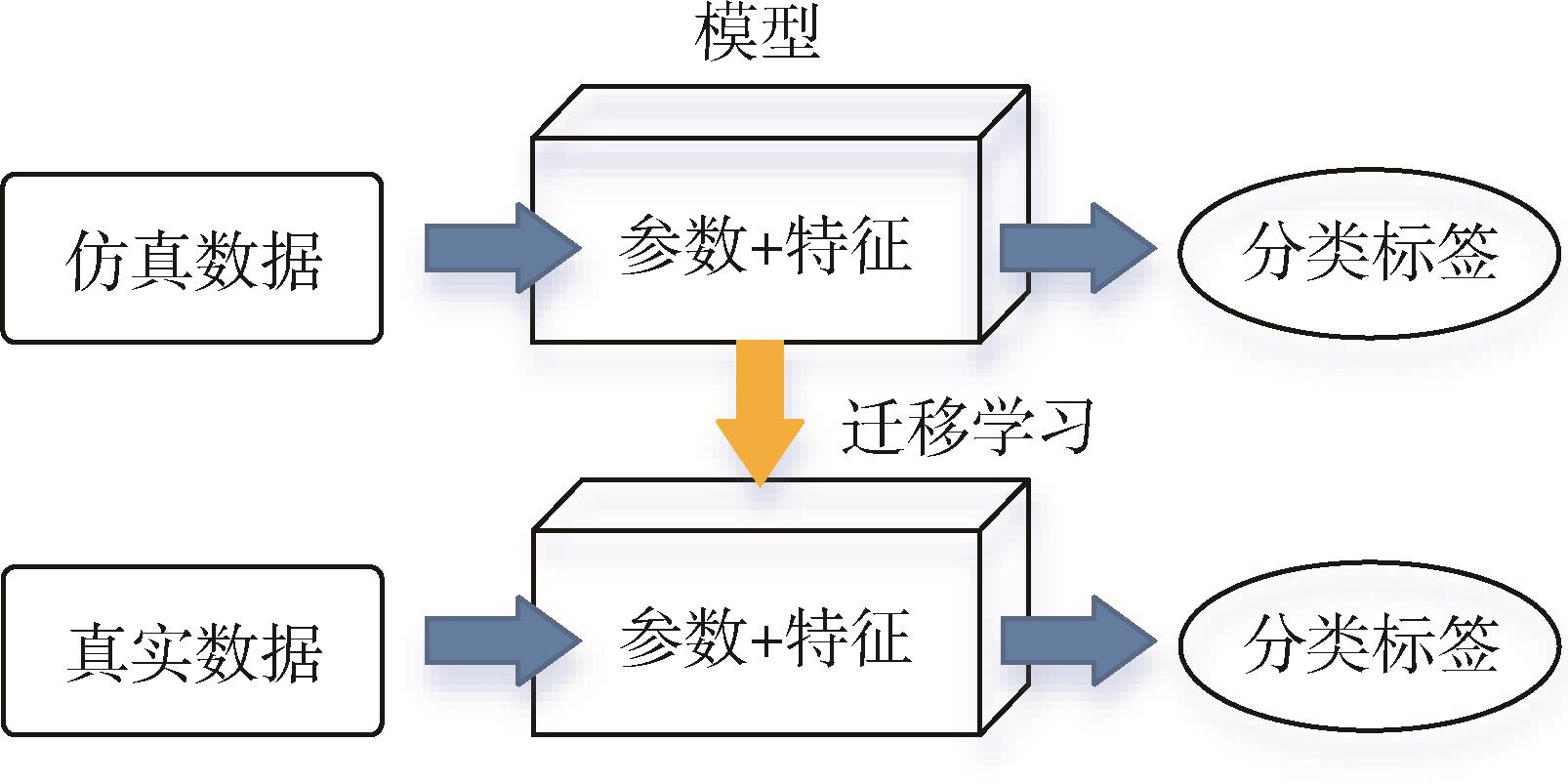
Fig. 8 Migration from simulation domain to real domain
| [1] | SIOURIS G M. Missile Guidance and Control Systems[M]. New York: Springer, 2004: B32. |
| [2] | 刘全, 翟建伟, 章宗长, 等. 深度强化学习综述[J]. 计算机学报, 2018, 41(1): 1-27. |
| LIU Quan, ZHAI Jianwei, ZHANG Zongchang, et al. A Survey on Deep Reinforcement Learning[J]. Chinese Journal of Computers, 2018, 41(1): 1-27. | |
| [3] | MIGNANTI S, GIORGIO A D, SURACI V. A Model Based RL Admission Control Algorithm for Next Generation Networks[C]∥2009 Eighth International Conference on Networks. Piscataway: IEEE, 2009: 191-196. |
| [4] | VEMULA A, SONG Yuda, SINGH A, et al. The Virtues of Laziness in Model-Based RL: A Unified Objective and Algorithms[C]∥Proceedings of the 40th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2023: 34978-35005. |
| [5] | 刘建伟, 高峰, 罗雄麟. 基于值函数和策略梯度的深度强化学习综述[J]. 计算机学报, 2019, 42(6): 1406-1438. |
| LIU Jianwei, GAO Feng, LUO Xionglin. Survey of Deep Reinforcement Learning Based on Value Function and Policy Gradient[J]. Chinese Journal of Computers, 2019, 42(6): 1406-1438. | |
| [6] | AMATO C. An Introduction to Decentralized Training and Execution in Cooperative Multi-agent Reinforcement Learning[EB/OL]. (2024-08-19) [2024-12-12]. . |
| [7] | AKBAR S, ADVE R S, DING Zhen, et al. Model-Based DRL for Task Scheduling in Dynamic Environments for Cognitive Multifunction Radar[C]∥2024 IEEE Radar Conference (RadarConf24). Piscataway: IEEE, 2024: 1-6. |
| [8] | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-Level Control Through Deep Reinforcement Learning[J]. Nature, 2015, 518(7540): 529-533. |
| [9] | VAN HASSELT H, GUEZ A, SILVER D. Deep Reinforcement Learning with Double Q-Learning[C]∥Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2016: 2094-2100. |
| [10] | SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized Experience Replay[EB/OL]. (2015-11-19) [2024-09-13]. . |
| [11] | WANG Ziyu, SCHAUL T, HESSEL M, et al. Dueling Network Architectures for Deep Reinforcement Learning[C]∥Proceedings of the 33rd International Conference on International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2016: 1995-2003. |
| [12] | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with Deep Reinforcement Learning[EB/OL]. (2013-12-19) [2024-09-13]. . |
| [13] | BELLEMARE M G, DABNEY W, MUNOS R. A Distributional Perspective on Reinforcement Learning[C]∥Proceedings of the 34th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2017: 449-458. |
| [14] | HESSEL M, MODAYIL J, VAN HASSELT H, et al. Rainbow: Combining Improvements in Deep Reinforcement Learning[EB/OL]. (2017-10-06) [2024-03-12]. . |
| [15] | ARJONA-MEDINA J A, GILLHOFER M, WIDRICH M, et al. RUDDER: Return Decomposition for Delayed Rewards[C]∥Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13566-13577. |
| [16] | WILLIAMS R J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning[J]. Machine Learning, 1992, 8(3): 229-256. |
| [17] | SCHULMAN J, MORITZ P, LEVINE S, et al. High-Dimensional Continuous Control Using Generalized Advantage Estimation[EB/OL]. (2018-10-20) [2024-03-12]. . |
| [18] | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust Region Policy Optimization[C]∥Proceedings of the 32nd International Conference on International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2015: 1889-1897. |
| [19] | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous Control with Deep Reinforcement Learning[EB/OL]. (2019-07-05) [2024-09-12]. . |
| [20] | FUJIMOTO S, HOOF H, MEGER D. Addressing Function Approximation Error in Actor-Critic Methods[C]∥Proceedings of the 35th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2018: 1587-1596. |
| [21] | HAARNOJA T, TANG Haoran, ABBEEL P, et al. Reinforcement Learning with Deep Energy-Based Policies[C]∥Proceedings of the 34th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2017: 1352-1361. |
| [22] | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-08-28) [2024-03-12]. . |
| [23] | 张江华, 梁培康, 刘逸平. 毫米波导引头系统设计与工程实现[M]. 北京: 国防工业出版社, 2017. |
| [24] | 先苏杰, 王康, 曾鑫, 等. 有限视场角下基于深度强化学习的落角约束制导律[J/OL]. 兵工学报. (2024-09-03) [2024-10-12]. . |
| XIAN Sujie, WANG Kang, ZENG Xin, et al. Guidance Law with Impact Angle Constraints Based on Deep Reinforcement Learning Under Limited Field of View[J/OL]. Acta Armamentarii. (2024-09-03) [2024-10-12]. . | |
| [25] | 梁晨, 王卫红, 赖超. 带攻击角度约束的深度强化元学习制导律[J]. 宇航学报, 2021, 42(5): 611-620. |
| LIANG Chen, WANG Weihong, LAI Chao. Deep Reinforcement Meta-learning Guidance with Impact Angle Constraint[J]. Journal of Astronautics, 2021, 42(5): 611-620. | |
| [26] | 白志会. 基于强化学习的拦截机动目标制导律研究[D]. 长沙: 国防科技大学, 2020. |
| BAI Zhihui. Research on Guidance Law of Intercepting Maneuvering Target Based on Reinforcement Learning[D]. Changsha: National University of Defense Technology, 2020. | |
| [27] | 韩国亮. 基于强化学习的末制导导引律设计[D]. 哈尔滨: 哈尔滨工业大学, 2019. |
| HAN Guoliang. Design on Termianl Guidance Law Based on Reinforcement Learning[D]. Harbin: Harbin Institute of Technology, 2019. | |
| [28] | HONG D, KIM M, PARK S. Study on Reinforcement Learning-Based Missile Guidance Law[J]. Applied Sciences, 2020, 10(18): 6567. |
| [29] | LIU Yekun, ZHANG Xiaoyu, LI Shoupeng, et al. Three Dimensional Coupled Sliding Mode Guidance Law Based on Reinforcement Learning[C]∥2024 43rd Chinese Control Conference (CCC). Piscataway: IEEE, 2024: 3907-3911. |
| [30] | GAUDET B, FURFARO R. Line of Sight Curvature for Missile Guidance Using Reinforcement Meta-Learning[C]∥AIAA SCITECH 2023 Forum. Reston: AIAA, 2023: AIAA 2023-1627. |
| [31] | GAUDET B, FURFARO R, LINARES R. Reinforcement Learning for Angle-Only Intercept Guidance of Maneuvering Targets[J]. Aerospace Science and Technology, 2020, 99: 105746. |
| [32] | LEE S, LEE Y, KIM Y, et al. Impact Angle Control Guidance Considering Seeker's Field-of-View Limit Based on Reinforcement Learning[J]. Journal of Guidance, Control, and Dynamics, 2023, 46(11): 2168-2182. |
| [33] | LI Chengxuan, CHENG Haoyu, WANG Junrui, et al. Multi-missile Cooperative Guidance Law Based on Deep Reinforcement Learning[C]∥Proceedings of 3rd 2023 International Conference on Autonomous Unmanned Systems (3rd ICAUS 2023). Singapore: Springer Nature Singapore, 2024: 370-379. |
| [34] | WANG Yuanhao, DU Guo, LIU Yi, et al. Anti-missile Firepower Allocation Based on Multi-agent Reinforcement Learning[C]∥Proceedings of 3rd 2023 International Conference on Autonomous Unmanned Systems (3rd ICAUS 2023). Singapore: Springer Nature Singapore, 2024: 160-169. |
| [35] | 张青龙, 赵斌, 许新鹏. 被动探测视场角约束下的深度强化学习制导方法[J]. 宇航学报, 2024, 45(8): 1281-1289. |
| ZHANG Qinglong, ZHAO Bin, XU Xinpeng. Deep Reinforcement Learning Guidance Method Considering the Field-of-View Angle Constraint of Passive Detection[J]. Journal of Astronautics, 2024, 45(8): 1281-1289. | |
| [36] | 李梦璇, 郭建国, 许新鹏, 等. 基于近端策略优化的制导律设计[J]. 空天防御, 2023, 6(4): 51-57. |
| LI Mengxuan, GUO Jianguo, XU Xinpeng, et al. Guidance Law Based on Proximal Policy Optimization[J]. Air & Space Defense, 2023, 6(4): 51-57. | |
| [37] | YU Jianglong, SHI Zhexin, DONG Xiwang, et al. Secure Cooperative Guidance Strategy for Multimissile System with Collision Avoidance[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(1): 1034-1047. |
| [38] | 陈中原, 韦文书, 陈万春. 基于强化学习的多发导弹协同攻击智能制导律[J]. 兵工学报, 2021, 42(8): 1638-1647. |
| CHEN Zhongyuan, WEI Wenshu, CHEN Wanchun. Reinforcement Learning-Based Intelligent Guidance Law for Cooperative Attack of Multiple Missiles[J]. Acta Armamentarii, 2021, 42(8): 1638-1647. | |
| [39] | XUE Yihao, YANG Rui, CHEN Xiaohan, et al. A Review on Transferability Estimation in Deep Transfer Learning[J]. IEEE Transactions on Artificial Intelligence, 2024, 5(12): 5894-5914. |
| [40] | GUO Wei, ZHUANG Fuzhen, ZHANG Xiao, et al. A Comprehensive Survey of Federated Transfer Learning: Challenges, Methods and Applications[J]. Frontiers of Computer Science, 2024, 18(6): 186356. |
| [1] | Haode LIN, Baoning LIU, Tao PAN, Zhe KONG. Design of a Sliding Mode Cooperative Terminal Guidance Law Against Maneuvering Target [J]. Modern Defense Technology, 2026, 54(1): 129-137. |
| [2] | Jin ZHANG, Gang WANG, Xiangke GUO, Tengda LI, Xiangyu LIU, Runyu HUANG. Research and Analysis on the Construction and Development of Air and Missile Defense Battle Kill Chains/Web [J]. Modern Defense Technology, 2025, 53(4): 18-26. |
| [3] | Kaiyuan YANG, Chao MING, Xiaoming WANG. An Angle-Constrained Cooperative Guidance Law Based on a Novel Second-Order Consensus Protocol [J]. Modern Defense Technology, 2025, 53(4): 83-92. |
| [4] | Qingtian ZHAO, Liwei LI, Xin CHEN, Lizhi HOU. Research and Enlightenment of Artificial Intelligence Defense Technology [J]. Modern Defense Technology, 2024, 52(3): 55-63. |
| [5] | Xiaobiao DUN, Xinbo ZHANG, Tong YIN, Jingzhu CAI, Hongyu LI, Chenglong YU, Jingya XIU. A Fuzzy Variable Coefficient Variable Structure Guidance Law with Terminal Line-of-Sight Angle Constraint [J]. Modern Defense Technology, 2023, 51(5): 67-76. |
| [6] | Baoyin YAO, Lei MAO, Zhibin WANG. Applications of Artificial Intelligence in Space Equipment [J]. Modern Defense Technology, 2023, 51(2): 33-42. |
| [7] | Jin ZHANG, Guoliang XU, Hao GUO. Application Analysis of Artificial Intelligence Technology in Foreign Shipborne Weapon System [J]. Modern Defense Technology, 2023, 51(1): 42-49. |
| [8] | Gui-dong LI, Hai-ying LU, Zhi-wei LI, Shi-shun WEI, Ou ZHANG. An Improved Optimal Guidance Law with Angle Constraint [J]. Modern Defense Technology, 2022, 50(5): 52-58. |
| [9] | Gang WU, Ke ZHANG. Finite Time Convergent Guidance Law for Intercepting Highly Maneuvering Targets [J]. Modern Defense Technology, 2022, 50(5): 43-51. |
| [10] | Jia-wei BAO, Xiao-ping TIAN, Yu-na LIU, Chang-kuan ZOU, Yu-qing ZHANG. Summary of Research on Security Issues of ADS-B Protocol [J]. Modern Defense Technology, 2022, 50(5): 28-35. |
| [11] | YAN Peng-hui, LIU Gang, MIAO Qian-shu. Research on Bias Proportional Navigation Guidance Law Based on Terminal Impact Angle Constraint [J]. Modern Defense Technology, 2021, 49(6): 43-48. |
| [12] | YAO Bao-yin, MAO Lei, XIAO Ke, QU Hui. Applications of Artificial Intelligence on the Optical Earth Observation [J]. Modern Defense Technology, 2021, 49(5): 26-31. |
| [13] | TANG Run-ze, ZHANG Cheng-long, LI Lin-lin, WANG Shi-kai. Research on Applications and Key Technologies of Multi-Weapons in Cross-Domain Intelligent Coordination Air Combat [J]. Modern Defense Technology, 2021, 49(2): 26-34. |
| [14] | LI Huan, LIU Xin-lu. Application of Intelligent Mines in Special Operations [J]. Modern Defense Technology, 2021, 49(2): 20-25. |
| [15] | WANG Qing, LIU Hua-hua. Intelligent Autonomous Decision-Making and Control of Morphing Aircraft [J]. Modern Defense Technology, 2020, 48(6): 5-11. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||


